

Java-基础知识
1.8新特性
Lambda表达式
函数式接口 函数式编程
方法引用和构造器调用
Stream API
接口中的默认方法和静态方法
新时间日期API
新时间日期 *
属性 | 含义 |
|---|---|
Instant | 代表的是时间戳 |
LocalDate | 代表日期,比如2020-01-14 |
LocalTime | 代表时刻,比如12:59:59 |
LocalDateTime | 代表具体时间 2020-01-12 12:22:26 |
ZonedDateTime | 代表一个包含时区的完整的日期时间,偏移量是以UTC/ 格林威治时间为基准的 |
Period | 代表时间段 |
ZoneOffset | 代表时区偏移量,比如:+8:00 |
Clock | 代表时钟,比如获取目前美国纽约的时间 |
接口中的默认方法和静态方法 *
Java 8允许我们给接口添加一个非抽象的方法实现,只需要使用 default关键字即可,这个特征又叫做扩展方法,示例如下:
代码如下:
interface Formula { double calculate(int a);
default double sqrt(int a) { return Math.sqrt(a); } }
Formula接口在拥有calculate方法之外同时还定义了sqrt方法,实现了Formula接口的子类只需要实现一个calculate方法,默认方法sqrt将在子类上可以直接使用。
Lambda *
首先看看在老版本的Java中是如何排列字符串的:
代码如下:
List<String> names = Arrays.asList("peterF", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() { @Override public int compare(String a, String b) { return b.compareTo(a); } });
只需要给静态方法 Collections.sort 传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。
在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
代码如下:
Collections.sort(names, (String a, String b) -> { return b.compareTo(a); });
看到了吧,代码变得更段且更具有可读性,但是实际上还可以写得更短:
代码如下:
Collections.sort(names, (String a, String b) -> b.compareTo(a));
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
代码如下:
Collections.sort(names, (a, b) -> b.compareTo(a));
Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还能作出什么更方便的东西来:
函数式接口 *
Lambda表达式是如何在java的类型系统中表示的呢?每一个lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。因为 默认方法 不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
我们可以将lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加 @FunctionalInterface 注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
public void testConverter() {
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted); // 123
}方法与构造函数引用
前一节中的代码还可以通过静态方法引用来表示:
代码如下:
Converter<String, Integer> converter = Integer::valueOf;
Integer converted = converter.convert("123");
System.out.println(converted); // 123
Java 8 允许你使用 :: 关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:
代码如下:
converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted); // "J"
接下来看看构造函数是如何使用::关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
代码如下:
class Person { String firstName; String lastName;
Person() {}
Person(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } }
接下来我们指定一个用来创建Person对象的对象工厂接口:
代码如下:
interface PersonFactory<P extends Person> { P create(String firstName, String lastName); }
这里我们使用构造函数引用来将他们关联起来,而不是实现一个完整的工厂:
代码如下:
PersonFactory<Person> personFactory = Person::new; Person person = personFactory.create("Peter", "Parker");
我们只需要使用 Person::new 来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的签名来选择合适的构造函数。
Lambda 作用域
在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
访问局部变量
我们可以直接在lambda表达式中访问外层的局部变量:
代码如下:
final int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
代码如下:
int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3
不过这里的num必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
代码如下:
int num = 1; Converter<Integer, String> stringConverter = (from) -> String.valueOf(from + num); num = 3;
在lambda表达式中试图修改num同样是不允许的。
数据类型
包装类型
Integer i1 = 127;
Integer i2 = 127;
System.out.println(i1 == i2); //true
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4); // false127是字面量,转成Integer类型的时候会调用Integer的valueOf方法,valueOf方法会缓存-128到127的Integer对象
String
String s1 = new String("abc");
String s2 = "abc";
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s3 == s2); // trues1的创建会生成两个对象,一个是String对象放到堆中,一个是abc是字符串常量对象;
s2是一个字符串常量对象,如果常量池中没有,会创建
intern()方法会检查字符串常量池中是否有对象,如果有对象,则直接使用;没有,则创建,并返回引用
String s1 = new String("abc");
int h1 = s1.hashCode();
// 在中间加N行代码,保证s1的引用不变,但是值变为abcd;考察反射
Field value = s1.getClass().getDeclaredField("value");
value.setAccessible(true);
value.set(s1, "abcd".toCharArray());
int h2 = s1.hashCode();
System.out.println("hash = " + (h1 == h2) + "; val = " + s1);String、 Stringbuffer、 Stringbuilderf的区别
String是不可变的,如果尝试去修改,会新生成一个字符串对象, Stringbuffer和 Stringbuilder 是可变的
Stringbuffer 是线程安全的, Stringbuilder是线程不安全的,所以在单线程环境下 Stringbuilder效率会更高
Stringbuffer的线程安全是通过synchronized关键字实现的
@Override
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}排序
int数组类型 *
如果数组元素个数小于NSERTION_SORT_THRESHOLD(47),那么使用改进的插入排序进行排序,
普通插入排序,1 2 3 5 7 4 5,a1 = 5, a2 = 2
成对插入排序(pair insertion sort, 其基本思想是一次取出两个未排序数组的元素,并且确保(a1>a2, 那么在a1找到位置后,a2的位置肯定在a1之前,继续查找即可
如果元素个数大于插入排序的阈值并且小于快速排序的阈值QUICKSORT_THRESHOLD(286),则使用改进的双轴快速排序进行排序
单轴快速排序,每次选择一个元素作为轴值pivot, 然后使用双指针将小于pivot移到pivot的左边,大于pivot的值移到右边,使得pivot处于最终位置,这个过程称为一次排序,对两边递归的调用一次排序可以得到最终的排序结果。
基准,单抽
双轴快速排序的基本思想是一次可以将两个元素放到最终位置上,假设这两个轴值为pivot1,pivot2, 那么一次排序后,最终数组被这两个元素划分成三块:<pivot1, >=pivot1并且<=pivot2, >pivot2。为了达到这种划分,我们需要三个指针来进行操作i,k,j, i左边的是小于pivot1的,j右边的是大于pivot1的,k用来扫描,当k和j相聚的时候,则扫描结束。
两个基准,
这里java使用的是5分位法找出5个位置,当5个位置元素均不相同,则使用2、4位置作为轴,进行快排
如果元素个数大于快速排序的阈值,根据数组的无序程度来判定继续使用哪种算法,无序程度通过将数组划分为不同的有序序列的个数来判定
如果有序序列的个数大于MAX_RUN_COUNT(67),则认为原数组基本无序,则仍然使用双轴快速排序
如果小于MAX_RUN_COUNT,则认为原数组基本有序,使用归并排序进行排序。
Object类型 *
如果数组元素个数小于MIN_MERGE(32), 二分插入排序binarySort方法进行排序,所谓二分排序,是指在插入的过程中,使用二分查找的方法查找待插入的位置,这种查找方法会比线性查找快一点。
如果大于MIN_MERGE,则将数组划分成多个有序块进行归并排序。
综上所述,无论是基本类型的排序还是Object类型的排序,都使用了多种排序的组合,这种组合的原因在于在不同的排序规模下,需要适应性的选用不同的排序方法,
在排序规模较小的情况下,复杂度为O(n^2)的插入排序能获得比 例如快速排序更好的排序性能
在数组基本有序的情况下,归并排序比快速排序相比是更好的选择。总的来说,根据不同的数组规模决定使用不同的排序方法。
不适用堆排序的原因,虽然堆排序的时间复杂度也是n*log(n),但是实际上堆排序的交换次数要多于快速排序
学习地址:https://blog.csdn.net/holmofy/article/details/71168530#t7
https://blog.csdn.net/holmofy/article/details/70245895
快速排序
单轴快速排序
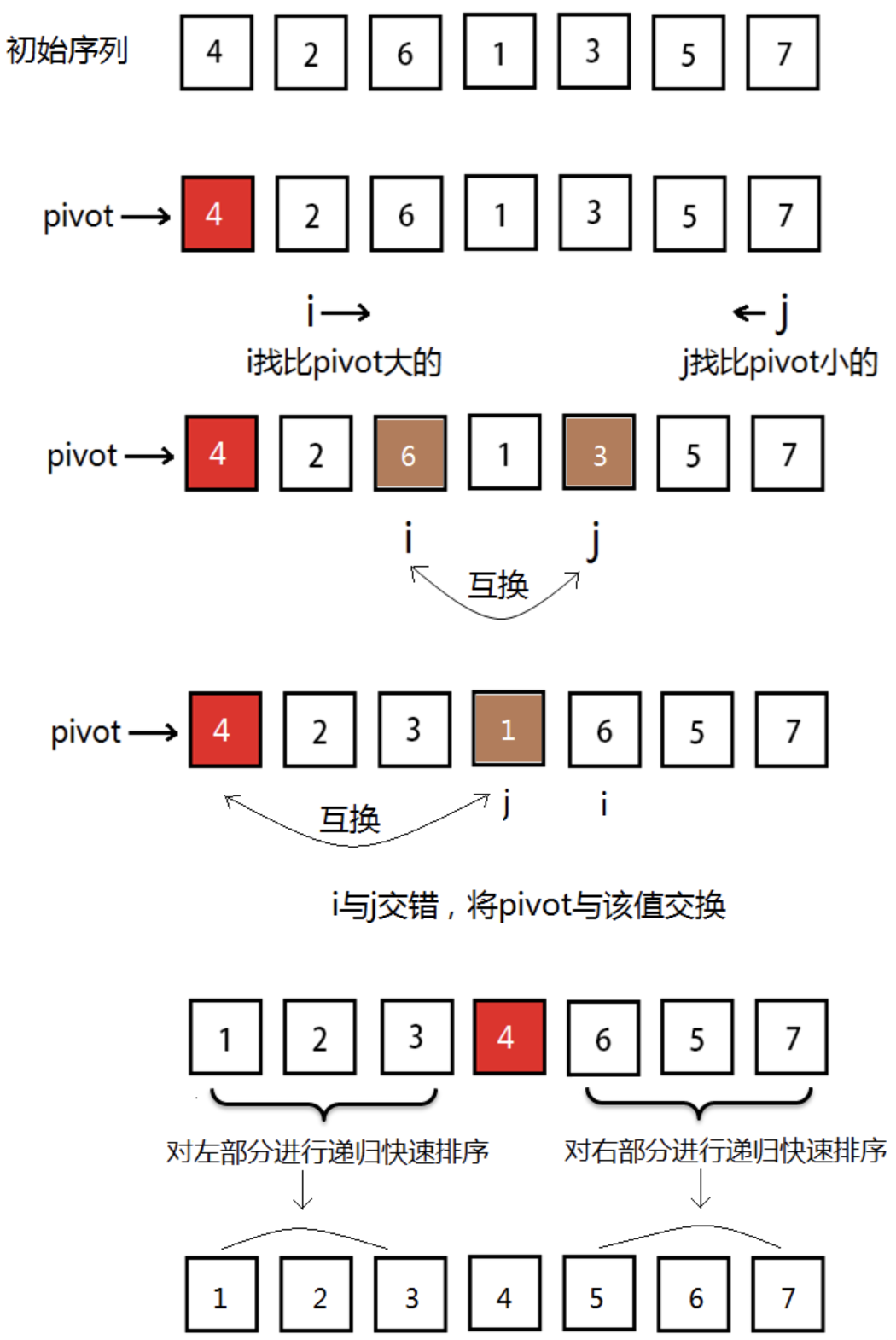
代码实现
/**
* 双端扫描交换 Double-End Scan and Swap
*/
public void deScanSwapSort(int[] items) {
deScanSwapSort(items, 0, items.length - 1);
}
public void deScanSwapSort(int[] items, int start, int end) {
if (start < end) {
int pivot = items[start];
int i = start + 1, j = end;
while (i <= j) {
while (i <= j && items[i] < pivot)
i++;
while (i <= j && items[j] >= pivot)
j--;
if (i <= j) {
swap(items, i, j);
}
}
swap(items, start, j);// 将中心点交换到中间。
deScanSwapSort(items, start, j - 1);// 中心点左半部分递归
deScanSwapSort(items, j + 1, end);// 中心点右半部分递归
}
}
private void swap(int[] items, int i, int j) {
int tmp = items[i];
items[i] = items[j];
items[j] = tmp;
}双轴快速排序
双轴快速排序,顾名思义,取两个中心点pivot1,pivot2,且pivot≤pivot2,可将序列分成三段:x<pivot1、pivot1≤x≤pivot2,x<pivot2,然后分别对三段进行递归。基本过程如下图:
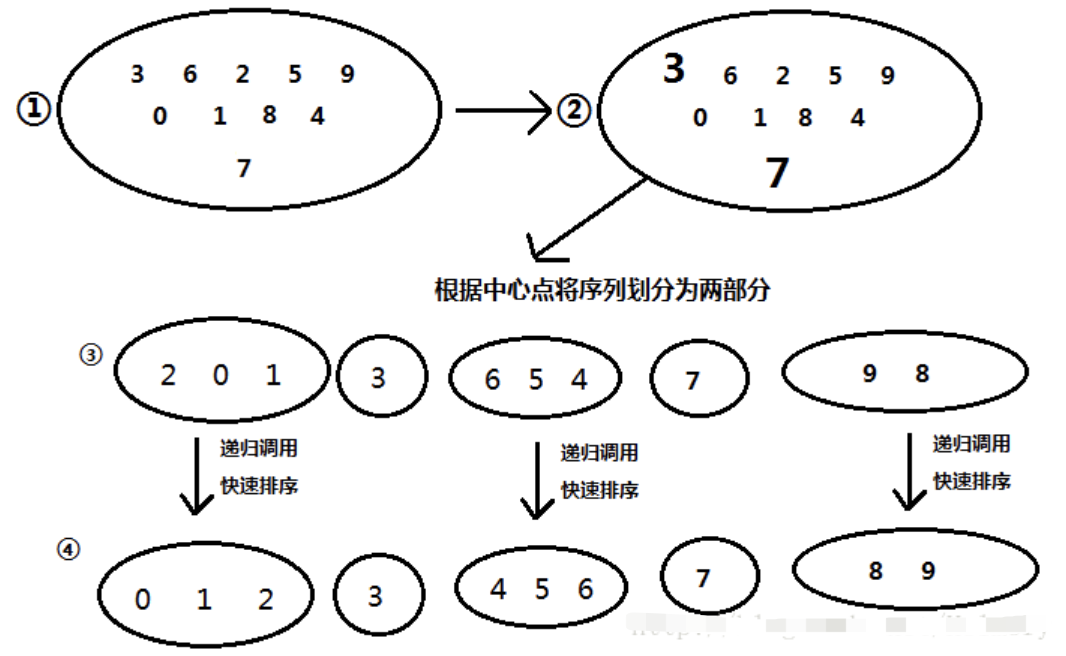
既然要两个中心点,我们一般将第一个元素和最后一个元素作为两个中心点。实现大致过程如下:
初始化时,i=start,j=end,k=start+1,k负责扫描。序列第一个值大于序列最后一个值,需要进行交换。然后pivot1=items[start],pivot2=items[end]。
扫描过程中保持:1~i是小于pivot1的元素,i~k是大于等于pivot1、小于等于pivot2的元素,j~end-1是大于pivot2的元素。

扫描
当k<pivot1,则++i与k做交换,k++
当k<=pivot2,则不需要动,k++
当k>pivot2,j开始递减查找小于pivot2的元素,找到元素
当j<pivot1,则k与j交换,k再与++i交换
当j>=pivot1,则k与j交换
k++
对三个区间进行递归
最后扫描完成,将pivot1与pivot2移到中间(这和之前讲的都差不多,就不在这进行过多的解释了)。
/**
* 双轴快排
*
* @param items
*/
public void dualPivotQuickSort(int[] items) {
dualPivotQuickSort(items, 0, items.length - 1);
}
public void dualPivotQuickSort(int[] items, int start, int end) {
if (start < end) {
if (items[start] > items[end]) {
swap(items, start, end);
}
int pivot1 = items[start], pivot2 = items[end];
int i = start, j = end, k = start + 1;
OUT_LOOP: while (k < j) {
if (items[k] < pivot1) { // 如果扫描为小于pivot1,则交换i+1和k
swap(items, ++i, k++);
} else if (items[k] <= pivot2) { // 如果大于pivot1&小于pivot2,则k++即可
k++;
} else {
while (items[--j] > pivot2) { // --j判断是否大于pivot2,找到比pivot2小的元素或者退出循环
if (j <= k) {
// 扫描终止
break OUT_LOOP;
}
}
if (items[j] < pivot1) { // 判断比pivot2小的元素是否同时小于pivot1,小于,则j和k交换,因为k大于pivot2,
swap(items, j, k); // j和k先交换,这样j的位置是大于pivot2的元素,k的位置小于pivot1的元素,所以k需要在于++交换
swap(items, ++i, k);
} else {
swap(items, j, k); // 不小于pivot1,直接交换k、j即可
}
k++; // 元素累加
}
}
swap(items, start, i); // 通过分区后,i的位置为当前pivot1的位置,与start交换;j同理
swap(items, end, j);
// 对三个区域递归
dualPivotQuickSort(items, start, i - 1);
dualPivotQuickSort(items, i + 1, j - 1);
dualPivotQuickSort(items, j + 1, end);
}
}