Java-volitale底层实现
内存屏障的实现涉及大量硬件架构层面的知识,又需要操作系统或JVM的配合才能发挥威力,单纯从任何一个层面都无法理解。本文整合了这三个层面的大量知识,篇幅较长,希望能在一篇文章内,把内存屏障的基本问题讲述清楚。
定义
happens-before中的volatile变量规则:对volatile变量的写入操作必须在对该变量的读操作之前执行。
volatile变量规则只是一种标准,要求JVM实现保证volatile变量的语义。语义的两个作用:
保持可见性
禁用重排序(读操作禁止重排序之后的操作,写操作禁止重排序之前的操作)
场景
单例模式
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}AQS源码(AbstractQueuedSynchronizer)
/**
* The synchronization state.
*/
private volatile int state;其他等等并发工具,也包括各种框架,例如netty,都有应用
可见性
可见性的定义常见于各种并发场景中,以多线程为例:当一个线程修改了线程共享变量的值,其它线程能够立即得知这个修改。
指令重排序
在执行程序时,编译器和处理器会对指令进行重排序,重排序分为:(之后会细化讲解)
编译器重排序:在不改变代码语义的情况下,优化性能而改变了代码执行顺序;
指令并行的重排序:处理器采用并行技术使多条指令重叠执行,在不存在数据依赖的情况下,改变机器指令的执行顺序;
内存系统的重排序:使用缓存和读写缓冲区时,加载和存储可能是乱序执行。

内存屏障/内存栅栏
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序(指令的重排序)和内存可见性(主内存数据的可见性)问题。Java编译器也会根据内存屏障的规则禁止重排序。(也就是让一个CPU处理单元中的内存状态对其它处理单元可见的一项技术。)
屏障类型 | 指令示例 | 理解 | 说明 |
|---|---|---|---|
LoadLoad Barrier | Load1:LoadLoad:Load2 | 禁止 读读的重排序 | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载 |
StoreStore Barrier | Store1:StoreStore:Store2 | 禁止写写的重排序 | 确保Store1数据对其他处理器可见(刷新到内存),之前于Store2及所有后续存储指令的存储 |
LoadStore Barrier | Load1:LoadStore:Store2 | 禁止读写的重排序 | 确保Load1数据的装载,之前于Store2及所有后续存储指令的存储 |
StoreLoad Barrier | Store1:StoreLoad:Load2 | 禁止写读的重排序 | 确保Store1数据对其他处理器可见(刷新到内存),之前于Load2及所有后续装载指令的装载。StoreLoad Barrier会使用该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。 |
StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他3 个屏障的效果。现代的多处理器大多支持该屏障
内存屏障阻碍了CPU采用优化技术来降低内存操作延迟,必须考虑因此带来的性能损失。为了达到最佳性能,最好是把要解决的问题模块化,这样处理器可以按单元执行任务,然后在任务单元的边界放上所有需要的内存屏障。
操作系统实现
内存屏障可以理解成一种规范,不同的操作系统(处理器)实现方式不一样【Ps:下文会用到】
Processor | LoadStore | LoadLoad | StoreStore | StoreLoad |
|---|---|---|---|---|
sparc-TSO | no | no | no | membar |
x86 | no | no | no | mfence、locked |
ia64 | combine with st.rel or ld.acq | ld.acq | st.rel | mf |
arm | dmb | dmb | dmb-st | dmb |
ppc | lwsync | hwsync | lwsync | hwsync |
alpha | mb | mb | wmb | mb |
pa-risc | no | no | no | no |
sparc:可扩展处理器架构(Scalable Processor ARChitecture)的缩写,是一种精简指令集计算机指令集架构,最早于1985年由Sun微系统所设计,也是SPARC国际公司的注册商标之一。
x86:泛指一系列基于Intel 8086且向后兼容的中央处理器指令集架构。最早的8086处理器于1978年由Intel推出,为16位微处理器。
ia64:英特尔安腾架构(Intel Itanium architecture),使用在Itanium处理器家族上的64位元指令集架构,由英特尔公司与惠普公司共同开发
arm:高级精简指令集机器(英语:Advanced RISC Machine,更早称作艾康精简指令集机器,Acorn RISC Machine),是一个精简指令集(RISC)处理器架构家族,其广泛地使用在许多嵌入式系统设计。安谋控股(ARM Holdings)开发此架构并授权其他公司使用,以供他们实现ARM的某一个架构,开发自主的系统单片机和系统模块
ppc:是一种基于精简指令集(RISC)的指令集架构 ISA(Instruction set architecture),其基本的设计源自IBM的POWER架构。
alpha:Alpha AXP,是由迪吉多公司开发的64位RISC指令集架构微处理器
pa-risc:处理器指令集架构(ISA),属于精简指令集架构。由惠普公司开发,所以它又被称为惠普精准指令集架构(Hewlett Packard Precision Architecture,缩写为HP/PA)
源码
反编译
我们先反编译一下class文件,看跟普通的有什么不同,我这里拿单例模式反编译了
源代码:
package 设计模式.单例模式;
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}编译好class文件后,我们javap一下
-v -verbose 输出附加信息
-p -private 显示所有类和成员
javap -v -p Singleton
public class 设计模式.单例模式.Singleton
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#21 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#22 // 设计模式/单例模式/Singleton.uniqueInstance:L设计模式/单例模式/Singleton;
#3 = Class #23 // 设计模式/单例模式/Singleton
#4 = Methodref #3.#21 // 设计模式/单例模式/Singleton."<init>":()V
#5 = Class #24 // java/lang/Object
#6 = Utf8 uniqueInstance
#7 = Utf8 L设计模式/单例模式/Singleton;
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 LocalVariableTable
#13 = Utf8 this
#14 = Utf8 getUniqueInstance
#15 = Utf8 ()L设计模式/单例模式/Singleton;
#16 = Utf8 StackMapTable
#17 = Class #24 // java/lang/Object
#18 = Class #25 // java/lang/Throwable
#19 = Utf8 SourceFile
#20 = Utf8 Singleton.java
#21 = NameAndType #8:#9 // "<init>":()V
#22 = NameAndType #6:#7 // uniqueInstance:L设计模式/单例模式/Singleton;
#23 = Utf8 设计模式/单例模式/Singleton
#24 = Utf8 java/lang/Object
#25 = Utf8 java/lang/Throwable
{
private static volatile 设计模式.单例模式.Singleton uniqueInstance;
descriptor: L设计模式/单例模式/Singleton;
flags: ACC_PRIVATE, ACC_STATIC, ACC_VOLATILE
private 设计模式.单例模式.Singleton();
descriptor: ()V
flags: ACC_PRIVATE
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 7: 0
line 8: 4
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this L设计模式/单例模式/Singleton;
public static 设计模式.单例模式.Singleton getUniqueInstance();
descriptor: ()L设计模式/单例模式/Singleton;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=0
0: getstatic #2 // Field uniqueInstance:L设计模式/单例模式/Singleton;
3: ifnonnull 37
6: ldc #3 // class 设计模式/单例模式/Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field uniqueInstance:L设计模式/单例模式/Singleton;
14: ifnonnull 27
17: new #3 // class 设计模式/单例模式/Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field uniqueInstance:L设计模式/单例模式/Singleton;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field uniqueInstance:L设计模式/单例模式/Singleton;
40: areturn
Exception table:
from to target type
11 29 32 any
32 35 32 any
LineNumberTable:
line 11: 0
line 12: 6
line 13: 11
line 14: 17
line 16: 27
line 18: 37
StackMapTable: number_of_entries = 3
frame_type = 252 /* append */
offset_delta = 27
locals = [ class java/lang/Object ]
frame_type = 68 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
}
SourceFile: "Singleton.java"我们着重看一下这里,反编译后volatile变量比其他变量多了一个flag,ACC_VOLATILE【着重点,后期会用到】
private static volatile 设计模式.单例模式.Singleton uniqueInstance;
descriptor: L设计模式/单例模式/Singleton;
flags: ACC_PRIVATE, ACC_STATIC, ACC_VOLATILEACC_VOLATILE
我们根据关键字 ACC_VOLATILE 在Hotspot源码里搜索一下(本文参考的事jdk8的源码),优先搜索到flags的解析

点开我们会看到具体作用,是一个方法,我们继续拿方法全局搜索

通过搜索我们会发现在jvm的字节码解释器有应用【PS:jvm有字节码解释器和模板解释器,模板解释器是汇编,可读性低,这里我们参考字节码解释器】

这里我分别截取出来两个地方的代码,部分内容删除,我们细化看一下实现
4.1 volatile的读变量
CASE(_getfield):
CASE(_getstatic):
{
u2 index;
ConstantPoolCacheEntry* cache;
index = Bytes::get_native_u2(pc+1);
...........
//
// Now store the result on the stack
//
TosState tos_type = cache->flag_state();
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
// azh_log 判断是否支持IRIW,不支持多拷贝原子cpu,则使用fence屏障
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence(); // azh_log fence屏障等价于storeload屏障
}
if (tos_type == atos) {
VERIFY_OOP(obj->obj_field_acquire(field_offset));
SET_STACK_OBJECT(obj->obj_field_acquire(field_offset), -1);
} else if (tos_type == itos) {
// azh_log int_field_acquire继续往下看,读取
SET_STACK_INT(obj->int_field_acquire(field_offset), -1);
} else if (tos_type == ltos) {
SET_STACK_LONG(obj->long_field_acquire(field_offset), 0);
MORE_STACK(1);
} else if (tos_type == btos || tos_type == ztos) {
SET_STACK_INT(obj->byte_field_acquire(field_offset), -1);
} else if (tos_type == ctos) {
SET_STACK_INT(obj->char_field_acquire(field_offset), -1);
} else if (tos_type == stos) {
SET_STACK_INT(obj->short_field_acquire(field_offset), -1);
} else if (tos_type == ftos) {
SET_STACK_FLOAT(obj->float_field_acquire(field_offset), -1);
} else {
SET_STACK_DOUBLE(obj->double_field_acquire(field_offset), 0);
MORE_STACK(1);
}
} else {
........(1)看一下case里面的变量,我们是不是特别熟悉,就是class文件反编译后的字节码内容,_getfield为普通变量的读,_getstatic为static变量的读【enmmmmm..............,原来这么简单😄】
(2)if (cache->is_volatile()) {继续往下看,这行代码会判断变量是否是 volatile 修饰的,我们进入if看一下,首先会有一个if,判断IRIW的【这个我查资料也没有找到,有知道的小伙伴可以告知一下😂】,翻译过来是:判断是否支持IRIW,不支持多拷贝原子cpu,则使用调用OrderAccess::fence()。
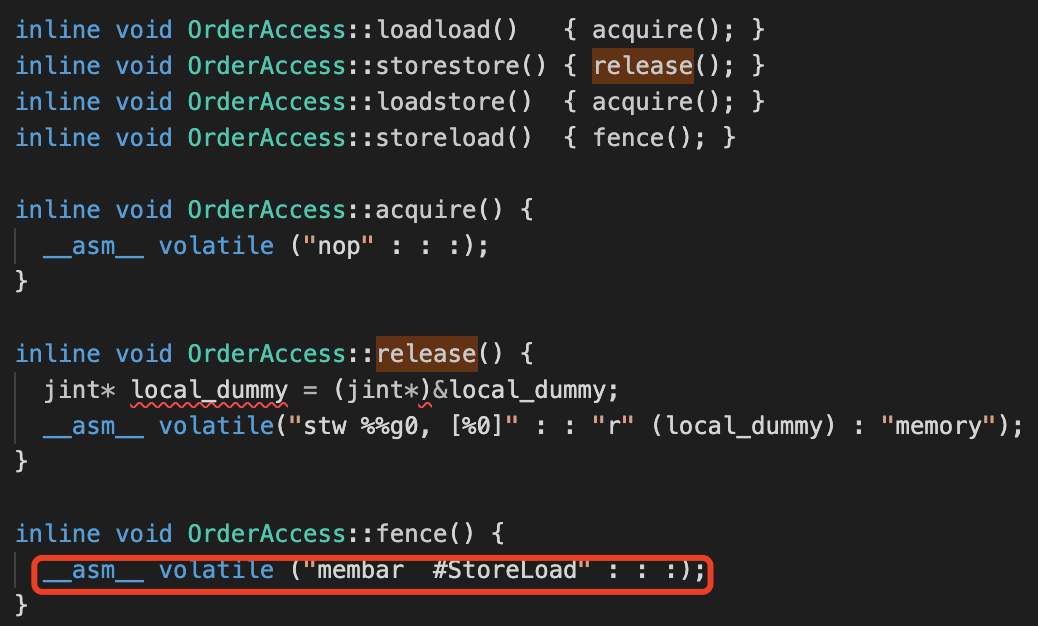
(3)继续点击OrderAccess::fence()会发现这个屏障的实现等价于storeload屏障,这里我们以 x86 OrderAccess实现为准,其他处理器的我们下文会有提到,我们通过源代码会看到【orderAccess_linux_x86.inline.hpp】
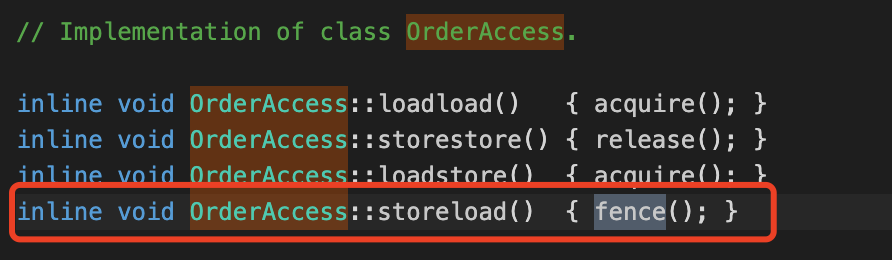
(4)继续往下看,会看到是通过判断一个类型 tos_type,调用不同的方法,简单一看会发现,tos_type 其实就类似变量类型,不同的类型调用不同的方法,这里我们以 int 为例,继续看一下,SET_STACK_INT这个通过名字就知道是往栈里设置值,那参数应该就是读取内存的值,方法为 int_field_acquire
(5)我们看一下int_field_acquire的实现,点进入会发现最终调用的是OrderAccess::load_acquire方法。

(6)我们还是以x86的OrderAccess的实现看一下,哎,发现也没有什么特殊操作啊,直接就返回值了,emmmm....蒙蔽了,然后我们看一下上面那个图👆🏻x86只实现了StoreLoad屏障,这个屏障在读取变量的时候不会用到,所以这里直接返回了。【x86之所以没有实现其他三个屏障,是因为Intel的MESI协议规定了,这个后期我们有机会谈一下】

(7)那我们看一下其他的处理器的实现,这里我随便找了一下实现类,点进入看一下【orderAccess_linux_zero.inline.hpp】。我们会看到,先读取了一个变量,然后调用了acquire方法,然后返回了变量data。我们继续跟踪看一下 acquire方法是干啥的,返现loadload、loadstore屏障最终都会调用acquire方法。

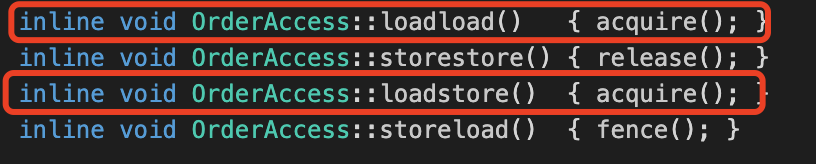
(8)恍然大悟,这不就是在volatile变量读后边添加loadload、loadstore屏障来禁止volatile读跟后面的读、写指令的重排序吗
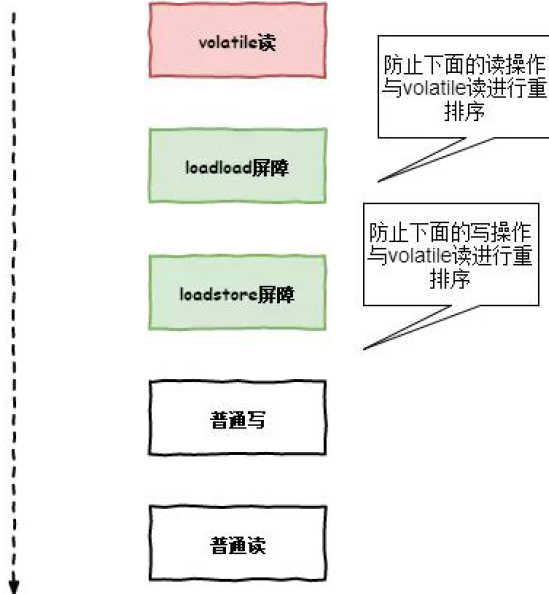
4.2 volatile的写变量
看懂了读,写就更简单了
CASE(_putfield): // azh_log 普通字段和静态字段的赋值
CASE(_putstatic):
{
u2 index = Bytes::get_native_u2(pc+1);
ConstantPoolCacheEntry* cache = cp->entry_at(index);
...........
//
// Now store the result
//
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) { // azh_log 检查是否有volatile修饰
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ztos) {
int bool_field = STACK_INT(-1); // only store LSB
obj->release_byte_field_put(field_offset, (bool_field & 1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
OrderAccess::storeload(); // azh_log 静态字段或普通字段的赋值,在volatile的写后加storeload屏障
} else {
...........(1)这里我们进入is_volatile的if语句中,这里我们也用int类型看一下,方法为release_int_field_put
(2)看到方法最终调用的是OrderAccess::release_store方法,继续点击看一下

(3)可以看到,在进行volatile变量写的时候,先调用了release方法,查一下release方法的调用,我们会发现,strostore屏障也是通过调用该方法实现的

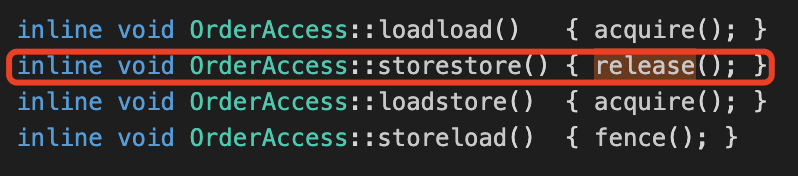
(4)回到最上层的if,继续往下看,我们会发现if出来之后,调用了OrderAccess::storeload(),也就是说在volatile变量写之后加了一个storeload屏障

(5)通过代码的阅读我们会发现,在volatile写之前会加storestore屏障,在写之后会加storeload屏障
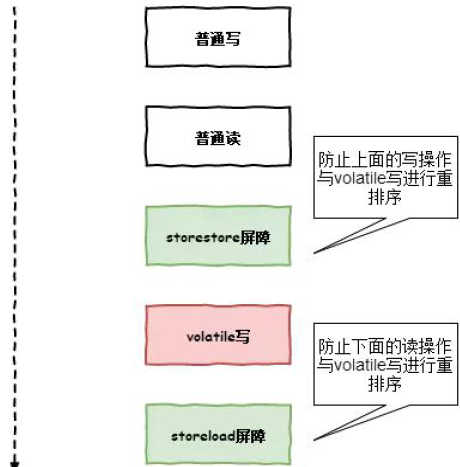
OrderAccess
通过上文,我们基本上可以看出来他的作用,它主要实现不同处理器的内存屏障,通过搜索我们会发现不同的操作系统不同处理器的实现
上问中操作系统实现我们提到不同操作系统的实现,这里我们找几个看一下
orderAccess_linux_x86.inline.hpp
最简单的是x86的,因为除了storeload屏障外,其他屏障都在协议规定了,不会有问题,所以没有实现;storeload是借助mfence或locked实现,我们看一下源码是不是这样。
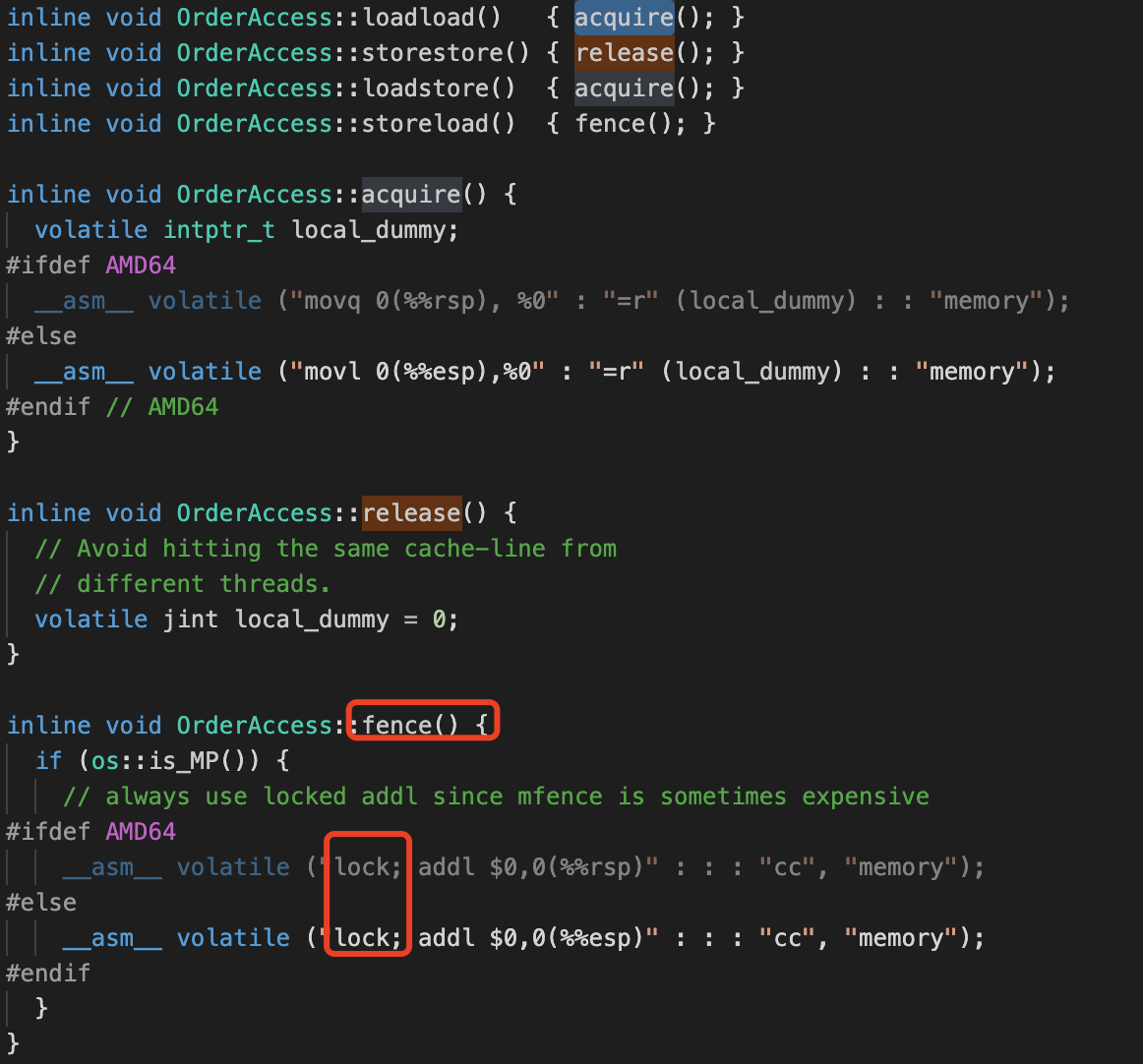
通过代码我们可以看到,storeload是借助lock;前缀实现的,早起的版本是通过mfence实现的,我们也可以看到备注上有这么一句话,always use locked addl since mfence is sometimes expensive mfence的使用是比较昂贵的,因为mfence不仅会清楚缓存,还会清理一些其他的内容,所以之后的版本优化使用lock;前缀
orderAccess_linux_sparc.inline.hpp
sparc跟x86差不多,也是只实现了storeload屏障,通过membar实现