Redis-知识汇总
数据类型
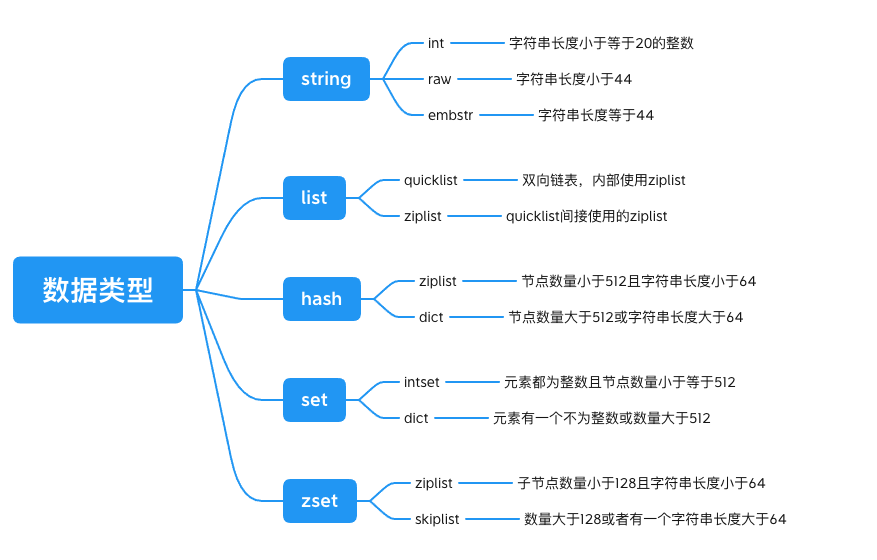
基本:string(字符串)、hash(字典)、set(集合)、list(列表)、sortset(有序集合)
string,key:value
key val
hash,user:3 name james age 18
格式:key val1 val2 val3
list(双端队列),mes:004 999
格式:key val
set,key member1 member2
格式:key val1 val2
使用场景
string
计数功能:INCR article:001
各类场景下(单机或分布式)的标识号【自增序列号或唯一id】
集群下的session共享
订单的自增
结合lua脚本可以实现分布式锁
hash
购物车
缓存
list
需要有序放入的、按照范围取值的都可以用
例如订阅的文章顺序
Set
朋友圈用户点赞
还有一些特殊的交集、并集、差集操作
例如,共同关注的人等等
zset
常用于排名/排序
底层实现
常用指令
TODO
持久化 *
rdb
aof
主从复制
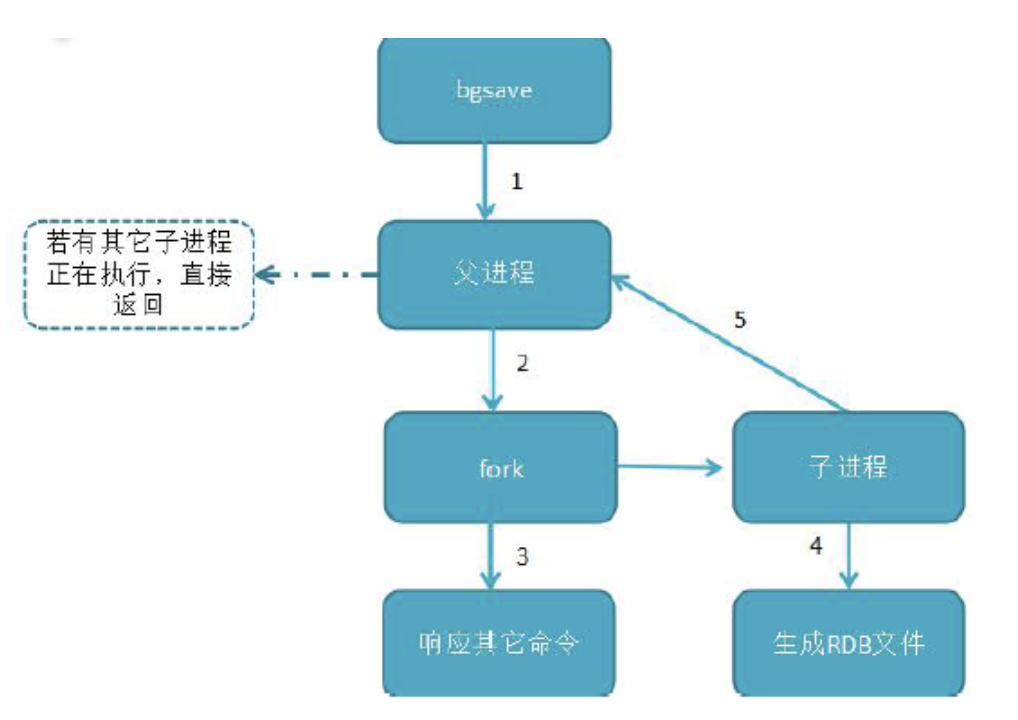
rdb
bgsave 命令:redis 进程执行fork 操作创建子线程,由子线程完成持久化,阻塞时间很短(微秒级),是save 的优化,在执行redis-cli shutdown 关闭redis 服务时,如果没有开启AOF 持久化,自动执行bgsave;
配置:
# 900秒内,如果超过1个key被修改,则发起快照保存
save 900 1
save 300 10
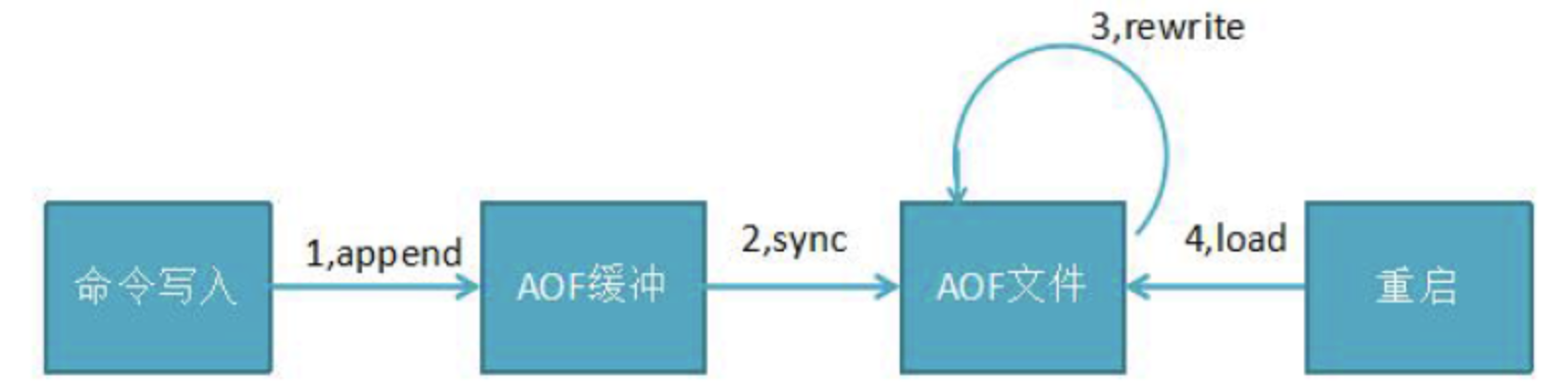
save 60 10000aof
所有的写入命令(set hset)会append 追加到aof_buf 缓冲区中
AOF 缓冲区向硬盘做sync 同步
随着AOF 文件越来越大,需定期对AOF 文件rewrite 重写,达到压缩
当redis 服务重启,可load 加载AOF 文件进行恢复
高版本:开启AOF,AOF是可以通过执行日志得到全部内存数据的方式,但是追求性能:
2.1:体积变大,重复无效指令 重写,后台用线程把内存的kv生成指令写个新的aof
4.x :把重写方式换成直接RDB放到aof文件的头部,比2.1的方法快了,再追加日志
配置:
# 开启aof
appendonly no
# appendfsync always # 每次操作都会立即写入aof文件中
appendfsync everysec # 每秒持久化一次(默认配置)
# appendfsync no # 不主动进行同步操作,默认30s一次
# 在aof文件体量超过64mb,且比上次重写后的体量增加了100%时自动触发重写
auto-aof-rewrite-percentage 100
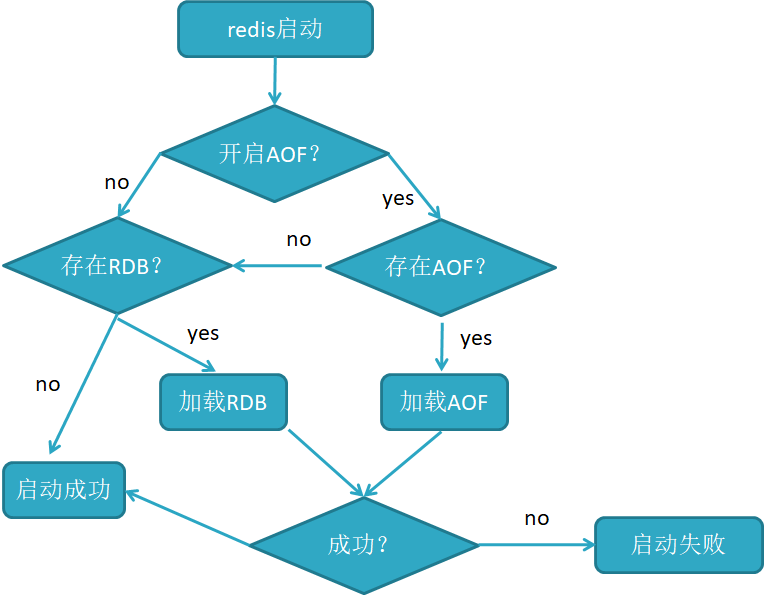
auto-aof-rewrite-min-size 64mb启动恢复过程
当AOF 和RDB 文件同时存在时,优先加载AOF
若关闭了AOF,加载RDB 文件
加载AOF/RDB 成功,redis 重启成功
AOF/RDB 存在错误,redis 启动失败并打印错误信息
数据淘汰
数据淘汰过程
淘汰数据的过程是在processCommand当中实现的,这里我们需要关注freeMemoryIfNeeded的方法。
整个数据淘汰过程如下:
遍历所有的db进行数据的释放
根据不同的策略选择从db.dict还是从db.expires选择待释放的数据
区分不同的淘汰策略选择不同的key,主要分为随机淘汰、LRU淘汰(最近最少使用的)、TTL时间淘汰。
随机淘汰
随机淘汰的场景下获取待删除key的策略,随机找hash桶再次hash指定位置的dictEntry即可。 就是在场景REDIS_MAXMEMORY_VOLATILE_RANDOM和REDIS_MAXMEMORY_ALLKEYS_LRU情况下的待淘汰的key。
LRU 策略
dictGetRandomKeys随机获取指定数目的dictEntry。
将获取的的dictEntry进行下sort按照最近时间进行排序。
选择最近使用时间最久远的数据进行过期
每次过期的数据其实是采样的结果数据中的最近未被访问数据而非全局的。
TTL时间淘汰
从expire中随机样本数据,TTL时间淘汰策略跟随机策略很像,唯一的区别就是TTL时间淘汰基于采样结果进行选择然后选择距离过期时间最近的数据进行过期,所以他理论上结合了采样+TTL时间计算进行数据淘汰的。
过期策略
memcached只是用了惰性删除,而redis同时使用了惰性删除与定期删除
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
惰性删除
含义:key过期的时候不删除,每次通过key获取值的时候去检查是否过期,若过期,则删除,返回null(用的时候再检查删除)。
优点:删除操作只发生在通过key取值的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
定期删除
含义:每隔一段时间执行一次删除过期key操作
优点:通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点定期删除过期key--处理"懒汉式删除"的缺点 缺点:在内存友好方面,不如"定时删除"(会造成一定的内存占用,但是没有懒汉式那么占用内存) 在CPU时间友好方面,不如"懒汉式删除"(会定期的去进行比较和删除操作,cpu方面不如懒汉式,但是比定时好) 难点:合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了),每次执行时间太长,或者执行频率太高对cpu都是一种压力。每次进行定期删除操作执行之后,需要记录遍历循环到了哪个标志位,以便下一次定期时间来时,从上次位置开始进行循环遍历
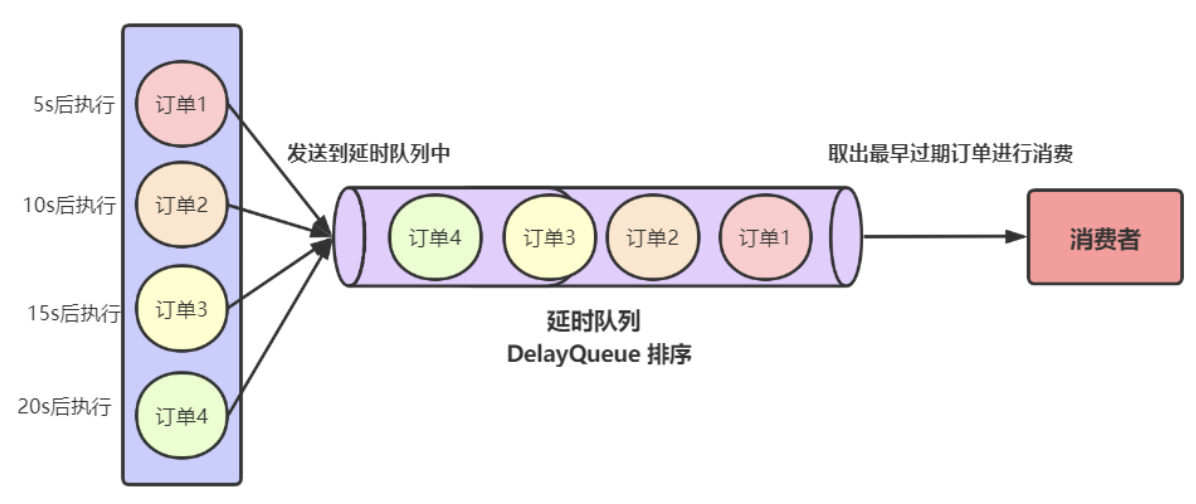
延时队列
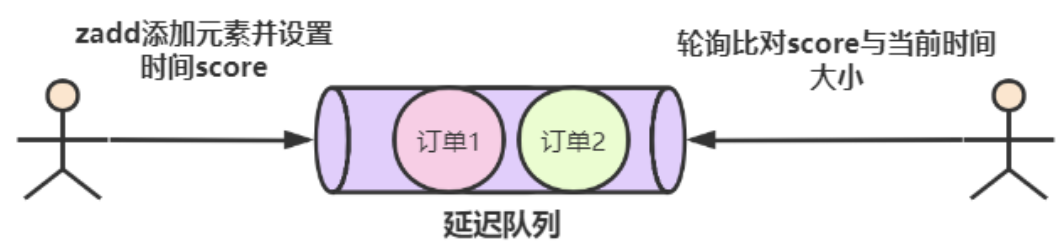
redis实现延迟队列
使用 zset(sortedset)这个命令,用设置好的时间戳作为score进行排序,使用 zadd score1 value1 ....命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过 zrangebyscore key min max withscores limit 0 1 查询最早的一条任务,来进行消费。
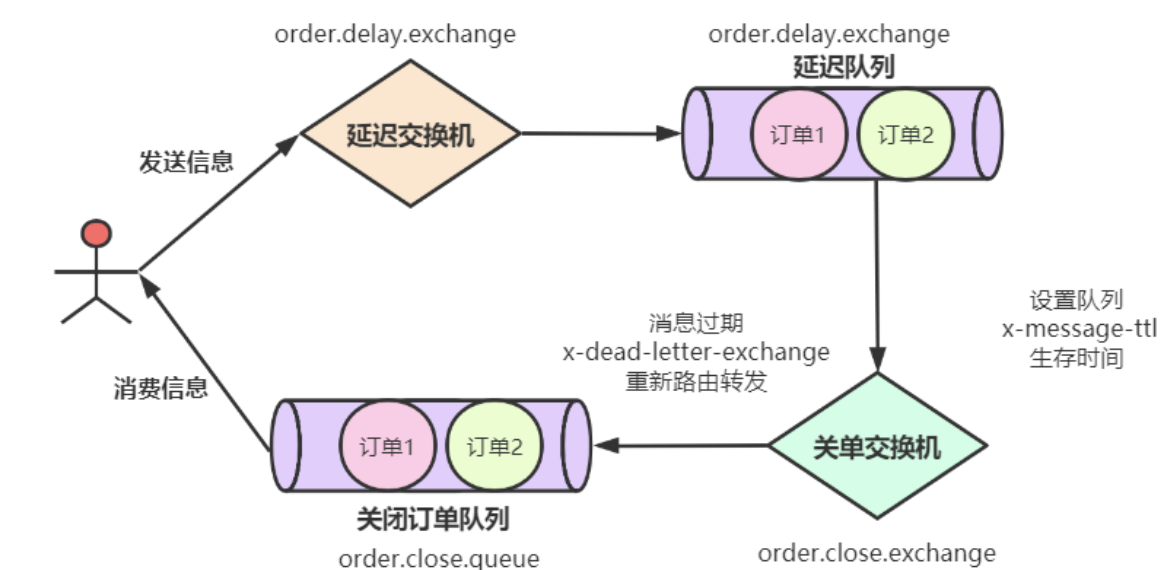
RabbitMQ 来实现延时队列
在MQ中我们可以对Queue设置 x-expires 过期时间或者对 Message设置超时时间x-message-ttl。
统一类型的消息需要用单独的队列以及单独的死信队列。MQ如果在队列设置ttl,则消息最靠前的也是即将过期的,所以删除简单;但是如果设置了消息的TTl,则检测是发生在消息即将投递的时候,避免扫描整个队列。
如果使用队列ttl,则只能有一个过期时间;如果使用消息的过期时间,则有延迟的问题,如果想要使用消息的过期时间,需要借助插件rabbitmq-delayed-message-exchange插件来实现延时队列。达到可投递时间时并将其通过 x-delayed-type 类型标记的交换机类型投递至目标队列。
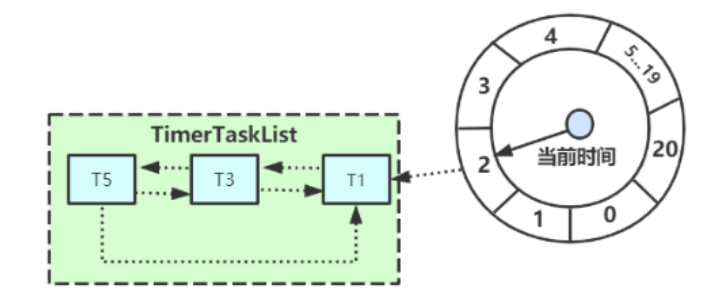
Kafka实现延时队
Kafka基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer),Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,可以进行相关的延时队列设置。
Netty实现延时队列
Netty也有基于时间轮算法来实现延时队列。Netty在构建延时队列主要用HashedWheelTimer,HashedWheelTimer底层数据结构是使用DelayedQueue,采用时间轮的算法来实现。
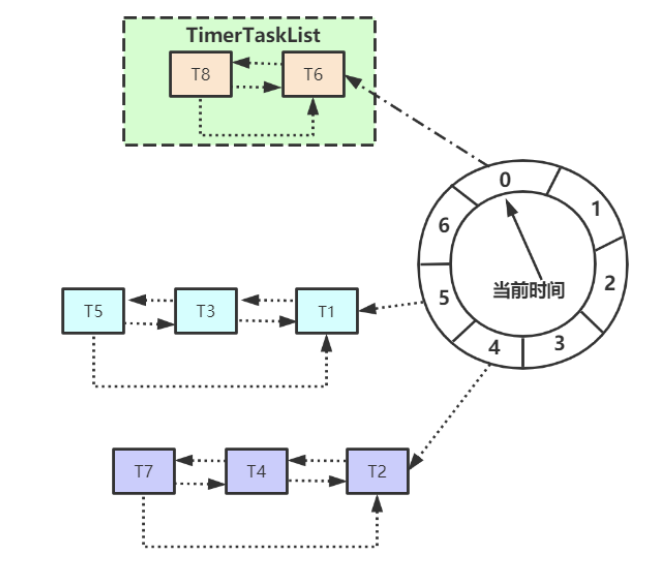
DelayQueue来实现延时队列
Java中有自带的DelayQueue数据类型,我们可以用这个来实现延时队列。DelayQueue是封装了一个PriorityQueue(优先队列),在向DelayQueue队列中添加元素时,会给元素一个Delay(延迟时间)作为排序条件,队列中最小的元素会优先放在队首,对于队列中的元素只有到了Delay时间才允许从队列中取出。这种实现方式是数据保存在内存中,可能面临数据丢失的情况,同时它是无法支持分布式系统的。