

Spring-知识汇总
启动流程
在创建 Spring容器,也就是启动 Spring时
首先会进行扫描,扫描得到所有的 BeanDefinition对象,并存在一个Map中
然后筛选出非懒加载的单例 BeanDefinition进行创建Bean,对于多例Bean不需要在启动过程中去进行创建,对于多例Bean会在每次获取Bean时利用 BeanDefinition去创建
利用 BeanDefinition创建Bean就是Bean的创建生命周期,这期间包括了合并 BeanDefinition、推断构造方法、实例化、属性填充、初始化前、初始化、初始化后等步骤,其中AOP就是发生在初始化后这一步骤中
单例Bean创建完了之后, Spring会发布一个容器启动事件
Spring启动结束
在源码中会更复杂,比如源码中会提供一些模板方法,让子类来实现,比如源码中还涉及到一些BeanfactoryPostProcessor和 Bean Postprocessor的注册, Spring的扫描就是通过BenafactoryPostprocessor来实现的,依赖注入就是通过 BeanfactoryPostProcessor来实现的
在 Spring启动过程中还会去处理@import等注解
ioc *
概括 **
总:
控制反转:理论思想,原来的对象是由使用者来进行控制,有了spring之后,可以把整个对象交给spring来帮我们进行管理
DI:依赖注入,把对应的属性的值注入到具体的对象中,@Autowired,populateBean完成属性值的注入
容器:存储对象,使用map结构来存储,在spring中一般存在三级缓存,singletonObjects存放完整的bean对象,
整个bean的生命周期,从创建到使用到销毁的过程全部都是由容器来管理(bean的生命周期)
分:
1、容器的创建过程(beanFactory,DefaultListableBeanFactory),向bean工厂中设置一些参数(BeanPostProcessor,Aware接口的子类)等等属性
2、加载解析bean对象,准备要创建的bean对象的定义对象beanDefinition,(xml或者注解的解析过程)
3、beanFactoryPostProcessor的处理,此处是扩展点,PlaceHolderConfigurSupport(解析占位符,${}),ConfigurationClassPostProcessor(配置属性的解析)
4、BeanPostProcessor的注册功能,方便后续对bean对象完成具体的扩展功能
5、通过反射的方式将BeanDefinition对象实例化成具体的bean对象,
6、bean对象的初始化过程(填充属性,调用aware子类的方法,调用BeanPostProcessor前置处理方法,调用init-mehtod方法,调用BeanPostProcessor的后置处理方法)
7、生成完整的bean对象,通过getBean方法可以直接获取
8、销毁过程
底层实现 *
反射,工厂,设计模式(会的说,不会的不说),关键的几个方法
createBeanFactory,getBean,doGetBean,createBean,doCreateBean,createBeanInstance(getDeclaredConstructor,newinstance),populateBean,initializingBean
1、先通过createBeanFactory创建出一个Bean工厂(DefaultListableBeanFactory)
2、开始循环创建对象,因为容器中的bean默认都是单例的,所以优先通过getBean,doGetBean从容器中查找,找不到的话,
3、通过createBean,doCreateBean方法,以反射的方式创建对象,一般情况下使用的是无参的构造方法(getDeclaredConstructor,newInstance)
4、进行对象的属性填充populateBean
5、进行其他的初始化操作(initializingBean)
核心概念
控制反转:bean的创建、初始化、销毁交给Spring容器处理
依赖注入:对象在初始化的时候,将依赖的对象通过某种方式注入bean(set、构造器等)
重要组件
BeanFactory
spring底层容器,定义了最基本的容器功能
ApplicationContext
ApplicationContext扩展自BeanFactory,拥有更加丰富的功能,例如国际化、事件机制、底层资源访问等等。
常用的几个ApplicationContext
FileSystemXmlApplicationContext :此容器从一个XML文件中加载beans的定义,XML Bean 配 置文件的全路径名必须提供给它的构造函数。
ClassPathXmlApplicationContext:此容器也从一个 XML 文件中加载 beans 的定义,这里你 需要正确设置 classpath 因为这个容器将在 classpath 里找 bean 配置。
WebXmlApplicationContext:此容器加载一个 XML 文件,此文件定义了一个 WEB 应用的所有 bean。
【简单来说BeanFactory是相对于Spring架构的,而ApplicationContext是相对于使用spring的开发人员】
Resource
bean的配置文件,一般为xml,保存bean信息的文件
BeanDefinition
定义了bean的基本信息,用它来创建bean
BeanPostProcessor
接口类型实例是针对某种特定功能的埋点,在这个点会根据接口类型来过滤掉不关注这个点的其他类,只有真正关注的类才会在这个点进行相应的功能实现。
获取有@Autowired 注解的构造函数埋点
SmartInstantiationAwareBeanPostProcessor
方法:determineCandidateConstructors
收集@Resource@Autowired@Value@PostConstruct,@PreDestroy 注解的方法和属性埋点
MergedBeanDefinitionPostProcessor
方法:postProcessMergedBeanDefinition
循环依赖解决中bean 的提前暴露埋点
SmartInstantiationAwareBeanPostProcessor
方法:getEarlyBeanReference
阻止依赖注入埋点
InstantiationAwareBeanPostProcessor
方法:postProcessAfterInstantiation
IOC/DI 依赖注入埋点
InstantiationAwareBeanPostProcessor
方法:postProcessProperties
BeanDefinition
id:bean的唯一表示,在xml文档中必须唯一
name:bean的别名
class:类的全限定名(包名+类名)
parent:父类bean
abstract:是否为抽象bean,抽象bean不用实例化
lazy-init:延迟加载,默认false,beanfactory启动的时候初始化,如果为true,调用到bean的时候初始化
autowire:自动装配的方式,默认不自动
NO:不自动装配
BY_NAME:根据name装配
BY_TYPE:根据type装配
CONSTRUCTOR:根据构造器装配,用于构造函数的参数的自动装配
AUTODETECT:通过某些机制决定,用构造器,还是类型
dependsOn:依赖对象,依赖对象的名称集合
init-method:bean的初始化方法,会在bean装配后调用,无参(方法名)
destroy-method:bean的销毁方法,他会在beanfactory关闭的时候调用,无参,只能用于单例的bean
factory-method:创建该bean对象的工厂方法
factory-bean:创建该bean对象的工厂类,配置后class属性无效
autowireCandidate:自动装配候选人,默认true,如果为false,则不会被其他类自动装配,但是它可以自动装配其他类
MutablePropertyValues:用于封装,存储类都有哪些属性值(?),list集合
ConstructorArgumentValues:存储构造器的参数,map集合,key为参数的顺序
MethodOverrides:用于封装lookup/replace method,set集合
核心流程
资源定位:找到配置文件
BeanDefinition载入、解析、注册
找到配置文件Resource。
将配置文件解析成BeanDefinition
将BeanDefinition向Map中注册 Map<name,beandefinition>
bean的实例化和依赖注入(由getbean方法触发)
通过反射或者Cglib的方式创造bean
根据配置的依赖将所需要的bean注入进来,此过程会递归调用getBean()方法。
根据bean的scope决定是否缓存该Bean,一般情况为单例。容器会缓存该对象。
bean的生命周期 **
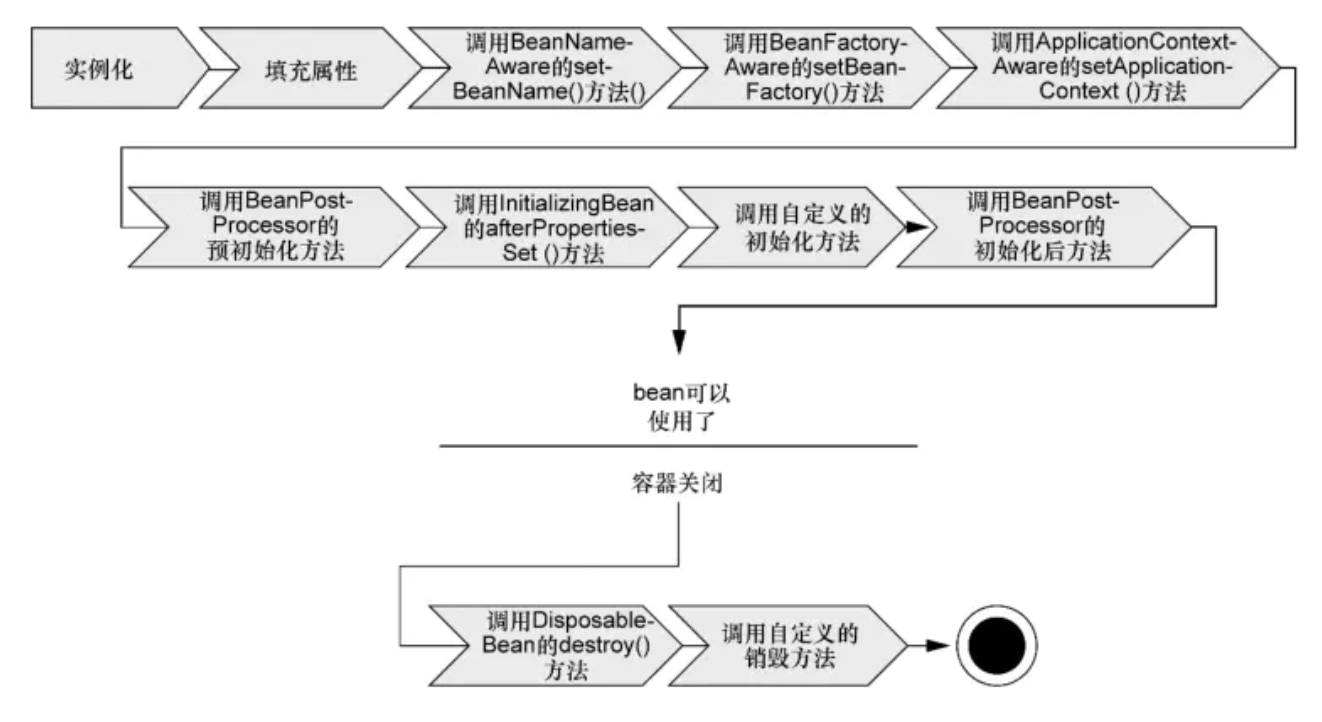
实例化bean:反射的方式生成对象
填充bean的属性:populateBean(),循环依赖的问题(三级缓存)
调用aware相关的方法 invokeAwareMethod(BeanNameAware->BeanFactoryAware->ApplicationContextAware[spring context工具类,获取context,通过context获取bean],策略的收集,工厂的初始化)
调用beanpostprocessor中的前置处理方法(埋点,收集注解、依赖注入、bean的提前暴露),即PostContract注解的方法
调用initmethod方法:invokeInitmethod(),判断是否实现了initializingBean接口,如果有,调用afterPropertiesSet方法,没有就不调用
调用BeanPostProcessor的后置处理方法:spring的aop就是在此处实现的,AbstractAutoProxyCreator
注册Destuction相关的回调接口:钩子函数
获取到完整的对象,可以通过getBean的方式来进行对象的获取
销毁流程,1;判断是否实现了DispoableBean接口,2,调用destroyMethod方法
调用自定义的销毁方法
名称 | 作用 |
|---|---|
BeanNameAware | 获得到容器中Bean的名称 |
BeanFactoryAware | 获得当前bean factory,这样可以调用容器的服务 |
ApplicationContextAware* | 获得当前application context,这样可以调用容器的服务 |
MessageSourceAware | 获得message source这样可以获得文本信息 |
ApplicationEventPublisherAware | 应用事件发布器,可以发布事件 |
ResourceLoaderAware | 获得资源加载器,可以获得外部资源文件 |
循环依赖的过程 **
循环依赖
不能解决的情况:
构造器注入循环依赖
Scope为prototype 多例模式
能解决的情况:
field属性注入(setter方法注入)循环依赖,例如@Autowired
三个级别的缓存
一级缓存:private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);
存储已经完成初始化的bean
删除:生成完整对象之后放到一级缓存,删除二三级缓存:addSingleton
二级缓存:private final Map<String, Object> earlySingletonObjects = new HashMap(16);
存储需要提前暴露,但没有完成初始化的bean
二级缓存可以在多级循环依赖的情况下,减少消耗的时间,如果每次都通过工厂去拿,便利所有的后置处理器判断是否创建代理对象等都会耗费时间。
例如:a引用了b和c,b引用了a,c引用了a;a开始实例化,发现依赖b,于是b开始实例化,但发现依赖a,于是调用a的工厂类创建,继续a的实例话,发现依赖c,c开始实例化,发现依赖a,如果此时没有二级缓存,c实例化,依赖的a需要再跳用工厂类创建。
删除:第一次从三级缓存确定对象是代理对象还是普通对象的时候,同时删除三级缓存 getSingleton
三级缓存:private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
存储需提前暴露的bean的工厂类,如果需要bean,需要调用工厂类的 getObject 方法
为什么需要?因为工厂类的getObject方法(确切的说是getEarlyBeanReference方法)中可以添加一些额外的初始化工作,而且存储的是函数式编程,只有调用的时候才会执行,减少耗时。
删除:createBeanInstance之后:addSingletonFactory
bean初始化的过程中会放入该map,初始化完成,移除,private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));
当这个Bean被创建完成后,会放入该map,private final Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
创建bean的流程
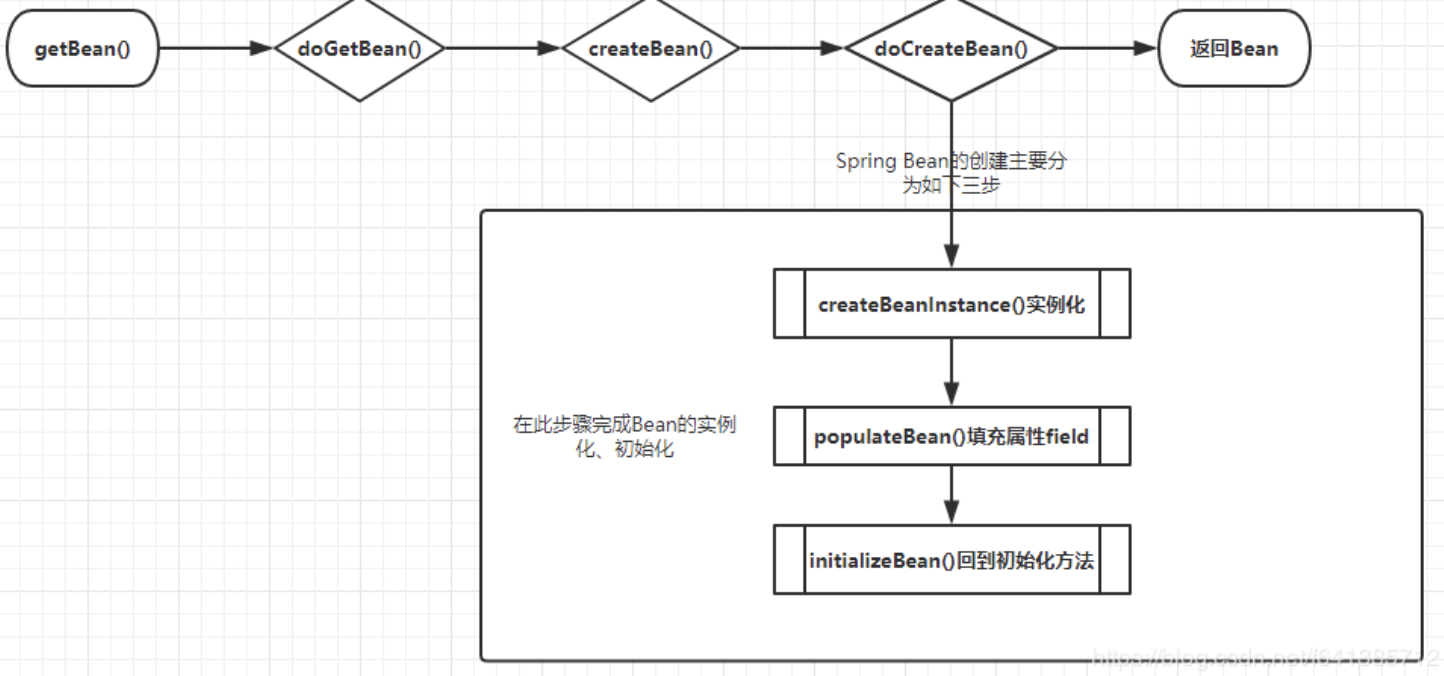
三个核心方法:
createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
populateBean:填充属性,这一步主要是对bean的依赖属性进行注入(@Autowired)
initializeBean:回到一些形如initMethod、InitializingBean等方法
缓存的生命周期
三级缓存
当earlySingletonExposure属性为true时,将beanFactory加入缓存;
当通过getSingleton从三级缓存中取出实例化的原始bean时或者完成初始化后,并清除singletonFactories中bean的缓存。
二级缓存
当earlySingletonExposure属性为true时,将beanFactory加入缓存,当通过getSingleton从三级缓存中取出实例化的原始bean时,此时,将获取的bean加入二级缓存。
当完成bean初始化,将bean加入一级缓存后,清除二级缓存;
一级缓存
当完成bean初始化,通过addSingleton将bean加入一级缓存singletonObjects中,并且这个缓存是常驻内存中的。
从上述分析可知,三级缓存和二级缓存是不共存的,且其在Spring完成初始化,都会被清除掉。
Bean是否线程安全
Spring本身并没有针对Bean做线程安全的处理
如果Bean是无状态的,那么Bean则是线程安全的
如果Bean是有状态的,那么Bean则不是线程安全的
另外,Bean是不是线程安全,跟Bean的作用域没有关系,Bean的作用域只是表示Bean的生命周期范围,对于任何生命周期的Bean都是一个对象,这个对象是不是线程安全的,还是得看这个Bean对象本身
Application Context和 Beanfactory区别
Beanfactory是 Spring中非常核心的组件,表示Bean工厂,可以生成Bean,维护Bean,而Applicationcontext继承了 Beanfactory,所以 Applicationcontext拥有 Beanfactory所有的特点,也是一个Bean工厂,但是 Applicationcontext除继承了 Beanfactory之外,还继承了诸如Environmentcapable、 Message Source、 Applicationeventpublisher等接口,从而Applicationcontext还有获取系统环境变量、国际化、事件发布等功能,这是 BeanFactory所不具备的
Bean Factory与FactoryBean区别**
相同点:都是用来创建bean对象的
不同点:使用BeanFactory创建对象的时候,必须要遵循严格的生命周期流程,太复杂了,,如果想要简单的自定义某个对象的创建,同时创建完成的对象想交给spring来管理,那么就需要实现FactroyBean接口了
isSingleton:是否是单例对象
getObjectType:获取返回对象的类型
getObject:自定义创建对象的过程(new,反射,动态代理)
设计模式**
DI(Dependecy Inject,依赖注入)是实现控制反转的一种设计模式,依赖注入就是将实例变量传入到一个对象中去。
工厂模式:Spring使用工厂模式可以通过
BeanFactory或ApplicationContext创建 bean 对象,factoryBean。单例模式:容器管理的对象默认都是单例,通过map存储,放入对象时使用同步代码
代理模式:aop
模版方法:(定义算法的骨架)Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类【一般情况下,我们都是使用继承的方式来实现模板模式,但是 Spring 并没有使用这种方式,而是使用Callback 模式与模板方法模式配合,既达到了代码复用的效果,同时增加了灵活性。】postProcessBeanFactory
观察者模式:spring的事件机制,事件监听机制,listener,event
适配器模式:(将一个接口转换成客户希望的另一个接口,接口不同,代理模式接口相同)
aop:将通知拦截器转换成对应的适配器(如:MethodBeforeAdviceInterceptor 负责适配 MethodBeforeAdvice)
mvc:由handleradapter执行handler(所谓的请求处理的方法),handleradapter通过反射执行具体的controller
装饰器模式:BeanWrapper、BeanDefinitionHolder,在不改变原有对象的基础上,将功能附加到对象上,提供了比继承更有弹性的方案(扩展原有对象的功能)
策略模式:InstantiationStretegy,根据不同的情况进行实例化;XmlBeanDefinitionReader,PropertiesBeanDefinitionReader
责任链模式:BeanPostProcessor
委派模式:比如:BeanDefinitionParserDelegate(解析xml中bean的定义)、ConstructorDelegate、MultipartResolutionDelegate、TypeConverterDelegate等。
原型模式:指定作用域为prototype
AOP *
概括 **
动态代理
aop是ioc的一个扩展功能,先有的ioc,再有的aop,只是在ioc的整个流程中新增的一个扩展点而已:BeanPostProcessor
总:aop概念(面向切面的编程)、应用场景(日志,拦截器,异常处理,事务)、动态代理(interface、cglib)
分:
bean的创建过程中有一个步骤可以对bean进行扩展实现,aop本身就是一个扩展功能,所以在BeanPostProcessor的后置处理方法中来进行实现
1、代理对象的创建过程(advice[通知],切面,切点)
2、通过jdk或者cglib的方式来生成代理对象
3、在执行方法调用的时候,会调用到生成的字节码文件中,直接回找到DynamicAdvisoredInterceptor类中的intercept方法,从此方法开始执行
4、根据之前定义好的通知来生成拦截器链
5、从拦截器链中依次获取每一个通知开始进行执行,在执行过程中,为了方便找到下一个通知是哪个,会有一个CglibMethodInvocation的对象,找的时候是从-1的位置一次开始查找并且执行的。
核心概念
AOP(Aspect-Oriented Programming:面向切面编程),能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
动态代理
代理
代理:通过某个对象创建了一个代理对象,不使用原对象而是使用代理对象
两种代理
静态代理:由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。
动态代理:在程序运行时,运用反射机制动态创建而成,无需手动编写代码。动态代理不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java反射机制可以生成任意类型的动态代理类。
动态代理
Spring AOP就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
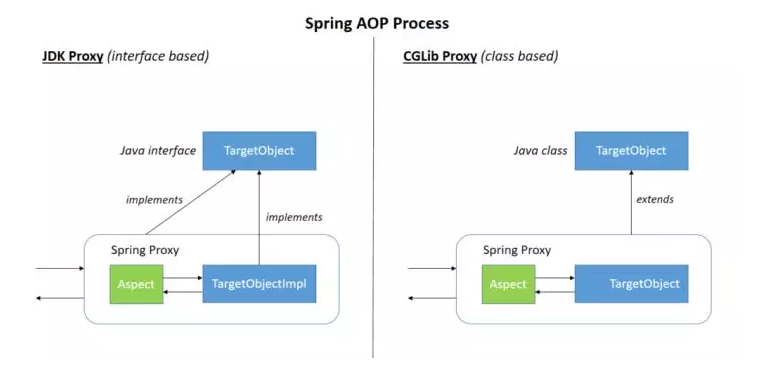
spring aop
通知类型
@Before,前置通知,执行方法前执行
@AfterReturn,返回通知,正常返回方法后执行
@After,后置通知,方法最终结束后执行,相当于finaly
@Around,环绕通知,围绕整个方法
@AfterThrowing,异常通知,抛出异常后执行
概念
Aspect,切面,一个关注点的模块。【包含增强和切点】
JoinPoint, 连接点,程序执行中的某个点,某个位置。【具体的切点】
PointCut,切点,切面匹配连接点的点,一般与切点表达式相关,就是切面如何切点。
Advice,通知(增强),指在切面的某个特定的连接点上执行的动作。
TargetObject,目标对象,指被切入的对象。 【被代理对象】
Weave,织入,将Advice作用在JoinPoint的过程。【生成代理对象的过程】
过程
bena实例化完成后,在初始化方法 initializeBean 判断是否生成代理对象
判断被代理类是否包含切面,包含,创建代理类
收集所有的增强和切点,封装成通知器(aop:advisor,aop:aspect没有本地区别,advisor组成了aspect)
如果有通知器,则生成代理类
创建代理工厂对象ProxyFactory
切面对象重新包装,会把自定义的MethodInterceptor 类型的类包装成Advisor切面类并加入到代理工厂中
根据proxyTargetClass 参数和是否实现接口来判断是采用jdk 代理还是cglib 代理
创建代理对象,并且把代理工厂对象传递到jdk 和cglib 中,注意这里的代理对象和jdk 类和cglib 类是一一对应的。
通过增强执行链将增强依次注入到代理对象中
事务
使用
编程式事务,在代码中硬编码。(不推荐使用)
声明式事务,在配置文件中配置(推荐使用)
基于XML的声明式事务
基于注解的声明式事务
隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT(默认): 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离(可重复读)级别 Oracle 默认采用的 READ_COMMITTED(读已提交)隔离级别.
TransactionDefinition.ISOLATION_READ_UNCOMMITTED(读未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
TransactionDefinition.ISOLATION_READ_COMMITTED(读已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
TransactionDefinition.ISOLATION_REPEATABLE_READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
TransactionDefinition.ISOLATION_SERIALIZABLE(串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
事务回滚 **
spring的事务管理是如何实现的?
总:spring的事务是由aop来实现的,首先要生成具体的代理对象,然后按照aop的整套流程来执行具体的操作逻辑,正常情况下要通过通知来完成核心功能,但是事务不是通过通知来实现的,而是通过一个TransactionInterceptor来实现的,然后调用invoke来实现具体的逻辑
分:1、先做准备工作,解析各个方法上事务相关的属性,根据具体的属性来判断是否开始新事务
2、当需要开启的时候,获取数据库连接,关闭自动提交功能,开起事务
3、执行具体的sql逻辑操作
4、在操作过程中,如果执行失败了,那么会通过completeTransactionAfterThrowing看来完成事务的回滚操作,回滚的具体逻辑是通过rollBack方法来实现的,实现的时候也是要先获取连接对象,通过连接对象来回滚
5、如果执行过程中,没有任何意外情况的发生,那么通过commitTransactionAfterReturning来完成事务的提交操作,提交的具体逻辑是通过commit方法来实现的,实现的时候也是要获取连接,通过连接对象来提交
6、当事务执行完毕之后需要清除相关的事务信息cleanupTransactionInfo
事务传播 **
支持当前事务
required(传播要求事务):如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。(默认)
supports(传播支持,以非事务运行): 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
mandatory(传播强制,抛异常): 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务:
requires_new(需要新的): 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
not_Support(不支持):以非事务方式运行,如果当前存在事务,则把当前事务挂起。
never(从不):以非事务方式运行,如果当前存在事务,则抛出异常。
嵌套事务:
nested(嵌套): 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于required。
关于事务挂起的举例:(某事务挂起之后,任何操作都不在该事务的控制之下)
概括 **
传播特性有几种?7种
Required,Requires_new,nested,Support,Not_Support,Never,Mandatory
某一个事务嵌套另一个事务的时候怎么办?
A方法调用B方法,AB方法都有事务,并且传播特性不同,那么A如果有异常,B怎么办,B如果有异常,A怎么办?
总:事务的传播特性指的是不同方法的嵌套调用过程中,事务应该如何进行处理,是用同一个事务还是不同的事务,当出现异常的时候会回滚还是提交,两个方法之间的相关影响,在日常工作中,使用比较多的是required,requires_new,nested
分:1、先说事务的不同分类,可以分为三类:支持当前事务,不支持当前事务,嵌套事务
2、如果外层方法是required,内层方法是,required,requires_new,nested
3、如果外层方法是requires_new,内层方法是,required,requires_new,nested
4、如果外层方法是nested,内层方法是,required,requires_new,nested
区分是否是同一个事务
如果外层方法中有事务,那么直接创建一个保存点,如果外层方法没有事务,那么就创建一个新的事务(required没有),后续操作中如果没有异常情况,那么会清除保存点信息,并且在外层事务中进行提交操作, 如果内层方法中存在异常情况,那么会回滚到保存点,外层方法事务会直接进行回滚, 如果外层方法中存在异常情况,那么会内层方法会正常执行,并且执行完毕之后释放保存点,并且外层方法事务会进行回滚
1、REQUIRED和NESTED回滚的区别 在回答两种方式区别的时候,最大的问题在于保存点的设置,很多同学会认为内部设置REQUIRED和NESTED效果是一样的,其实在外层方法对内层方法的异常情况在进行捕获的时候区别很大,两者报的异常信息都不同,使用REQUIRED的时候,会报Transaction rolled back because it has been marked as rollback-only信息,因为内部异常了,设置了回滚标记,外部捕获之后,要进行事务的提交,此时发现有回滚标记,那么意味着要回滚,所以会报异常,而NESTED不会发证这种情况,因为在回滚的时候把回滚标记清除了,外部捕获异常后去提交,没发现回滚标记,就可以正常提交了。
2、REQUIRED_NEW和NESTED区别 这两种方式产生的效果是一样的,但是REQUIRED_NEW会有新的连接生成,而NESTED使用的是当前事务的连接,而且NESTED还可以回滚到保存点,REQUIRED_NEW每次都是一个新的事务,没有办法控制其他事务的回滚,但NESTED其实是一个事务,外层事务可以控制内层事务的回滚,内层就算没有异常,外层出现异常,也可以全部回滚。
常见问题
内部调用方法失败代理失败的问题,内部直接方法a调用方法b,实际执行的是被代理对象的原方法,需要注入代理对象调用,也就是说可以通过autowired方法注入自己,实际注入的是代理类对象,通过这个对象去调用b方法
注意:transactional注解于是aop实现的,也会有这种问题
方法是私有化的方法,不会被代理
实现
Spring事务底层是基于数据库事务和AOP机制的
首先对于使用了@Transactiona注解的Bean, Spring会创建一个代理对象作为Bean
当调用代理对象的方法时,会先判断该方法上是否加了@Transactiona注解
如果加了,那么则利用事务管理器创建一个数据库连接
并且修改数据库连接的 autocommit属性为 false,禁止此连接的自动提交,这是实现 Spring事务非常重要的一步
然后执行当前方法,方法中会执行sql
执行完当前方法后,如果没有出现异常就直接提交事务
如果岀现了异常,并且这个异常是需要回滚的就会回滚事务,否则仍然提交事务
Spring事务的隔离级别对应的就是数据库的隔离级别
Spring事务的传播机制是 Spring事务自己实现的,也是 Spring事务中最复杂的
Spring事务的传播机制是基于数据库连接来做的,一个数据库连接一个事务,如果传播机制配置为需要新开一个事务,那么实际上就是先建立一个数据库连接,在此新数据库连接上执行sql
看一下跳槽涨薪涨薪
常用注解
1、@SpringBootApplication
包含@Configuration、@EnableAutoConfiguration、@ComponentScan
通常用在主类上。
2、@Repository
用于标注数据访问组件,即DAO组件。
3、@Service
用于标注业务层组件。
4、@RestController
用于标注控制层组件(如struts中的action),包含@Controller和@ResponseBody
5、@ResponseBody
表示该方法的返回结果直接写入HTTP response body中
一般在异步获取数据时使用,在使用@RequestMapping后,返回值通常解析为跳转路径,加上@responsebody后返回结果不会被解析
为跳转路径,而是直接写入HTTP response body中。比如异步获取json数据,加上@responsebody后,会直接返回json数据。
6、@Component
泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
7、@ComponentScan
组件扫描。相当于,如果扫描到有@Component @Controller @Service等这些注解的类,则把
这些类注册为bean。
8、@Configuration
指出该类是 Bean 配置的信息源,相当于XML中的,一般加在主类上。
9、@Bean
相当于XML中的,放在方法的上面,而不是类,意思是产生一个bean,并交给spring管理。
10、@EnableAutoConfiguration
让 Spring Boot 根据应用所声明的依赖来对 Spring 框架进行自动配置,一般加在主类上。
11、@AutoWired
byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。 当加上(required=false)时,就算找不到bean也不报错。
12、@Qualifier
当有多个同一类型的Bean时,可以用@Qualifier("name")来指定。与@Autowired配合使用
13、@Resource(name="name",type="type")
没有括号内内容的话,默认byName。与@Autowired干类似的事。
14、@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
该注解有六个属性:
params:指定request中必须包含某些参数值是,才让该方法处理。
headers:指定request中必须包含某些指定的header值,才能让该方法处理请求。
value:指定请求的实际地址,指定的地址可以是URI Template 模式
method:指定请求的method类型, GET、POST、PUT、DELETE等
consumes:指定处理请求的提交内容类型(Content-Type),如application/json,text/html;
produces:指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回