Netty-知识汇总
Netty 线程模型
netty线程模型(默认) *
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件,由对应的Handler处理。
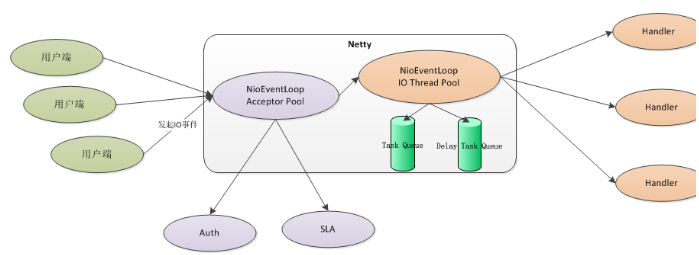
acceptor pool 是boss线程池,io thread pool 是work线程池
boss线程池详细作用:
接收客户端的tcp连接,初始化channel对象
将链路状态变更事件通知给ChannelPipeoline
work线程池的详细作用
异步读取通信对端的数据报,发送读事件到ChannelPipeoline
异步发送消息到通信对端,调用ChannelPipeoline的消息发送接口
执行系统调用的task(Task Queue)
执行定时任务task,例如链路空闲状态监听定时任务(Delay Task Queue)
NioEventLoop的处理链
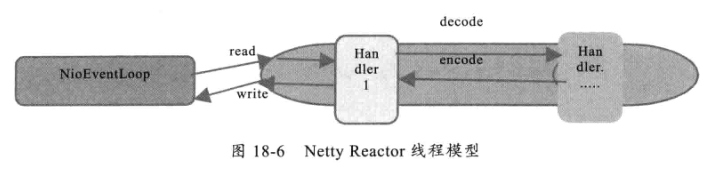
单线程模型
单线程模型:所有I/O操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请求或应答/响应消息。一个NIO 线程同时处理成百上千的链路,性能上无法支撑,速度慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。
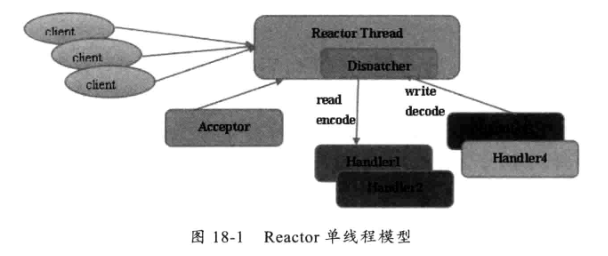
通过acceptor类接收客户端发送的请求,接收到请求后,通过dispatcher派送消息到指定的handler上处理,然后通过nio线程将消息发送给客户端
多线程模型
多线程模型:有一个NIO 线程(Acceptor) 只负责监听服务端,接收客户端的TCP 连接请求;NIO 线程池负责网络IO 的操作,即消息的读取、解码、编码和发送;1 个NIO 线程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,这是为了防止发生并发操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor 线程可能会存在性能不足问题。
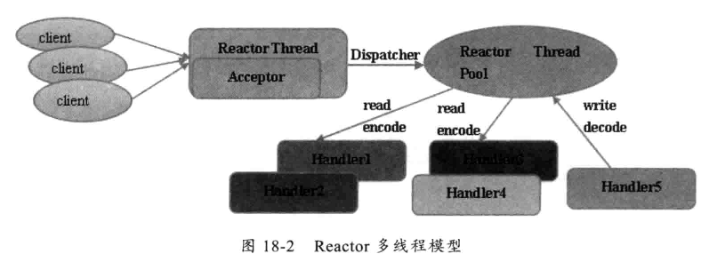
问题:如果有百万的客户端连接或者客户端连接需要安全认真,而且安全认证又是很耗时的操作情况下,多线程模型是不满足需求的。
主从多线程模型(netty官方推荐使用)
主从多线程模型:Acceptor 线程用于绑定监听端口,接收客户端连接,将新创建的SocketChannel 从主线程池的Reactor 线程的多路复用器上移除,重新注册到Sub (从) 线程池的线程上,用于处理I/O 的读写等操作,从而保证mainReactor只负责接入认证、握手等操作;
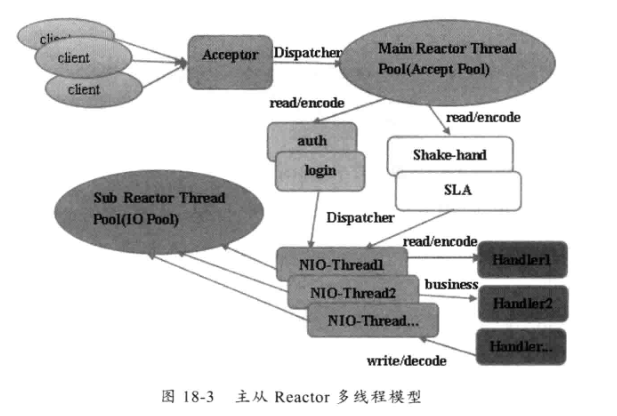
Acceptor
请求接收者,在实践时其职责类似服务器,并不真正负责连接请求的建立,而只将其请求委托 Main Reactor 线程池来实现,起到一个转发的作用。
Main Reactor 主 Reactor 线程组,主要负责连接事件,并将IO读写请求转发到 SubReactor 线程池。当然在一些需要对客户端进行权限控制等场景下,权限校验的职责可以放到 Main Reactor 线程池,即 Main Reactor 也可以注册通道的读写事件,读取客户端权限校验相关的数据包,执行权限验证,权限验证通过后再将2通道注册到IO线程。
Sub Reactor Main Reactor 通常监听客户端连接后会将通道的读写转发到 Sub Reactor 线程池中一个线程(负载均衡),负责数据的读写。在 NIO 中 通常注册通道的读(OP_READ)、写事件(OP_WRITE)。
Netty 为什么如此高效 *
非阻塞IO
Netty采用了IO多路复用技术,让多个IO的阻塞复用到一个select线程阻塞上,能够有效的应对大量的并发请求
高效的Reactor线程模型
Netty服务端采用Reactor主从多线程模型
主线程:Acceptor 线程池用于监听Client 的TCP 连接请求
从线程:Client 的IO 操作都由一个特定的NIO 线程池负责,负责消息的读取、解码、编码和发送
Client连接有很多,但是NIO 线程数是比较少的,一个NIO 线程可以同时绑定到多个Client,同时一个Client只能对应一个线程,避免出现线程安全问题
无锁化串行设计
串行设计:消息的处理尽可能在一个线程内完成,期间不进行线程切换,避免了多线程竞争和同步锁的使用,减少性能开销。
高效的并发编程
Netty 的高效并发编程主要体现在如下几点
volatile 的大量、正确使用
CAS 和原子类的广泛使用
线程安全容器的使用
通过读写锁提升并发性能
高性能的序列化框架
Netty 默认提供了对Google Protobuf 的支持,通过扩展Netty 的编解码接口,可以实现其它的高性能序列化框架
零拷贝
Netty 的接收和发送ByteBuffer 采用DirectByteBuffer,使用堆外直接内存进行Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HeapByteBuffer)进行Socket 读写,JVM 会将堆内存Buffer 拷贝一份到直接内存中,然后才写入Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝
Netty 提供了组合Buffer 对象,可以聚合多个ByteBuffer 对象,用户可以像操作一个Buffer 那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer 合并成一个大的Buffer。
Netty 的文件传输采用了transferTo()方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write()方式导致的内存拷贝问题。
内存池
基于对象池的 ByteBuf可以重用 ByteBuf对象,内部维护了一个内存池,可以循环利用已创建的 ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。测试表明使用内存池后的Nety在高负载、大并发的冲击下内存和GC更加平稳
灵活的TCP 参数配置能力
合理设置TCP 参数在某些场景下对于性能的提升可以起到显著的效果,例如SO_RCVBUF 和SO_SNDBUF。如果设置不当,对性能的影响是非常大的
SO_RCVBUF 和SO_SNDBUF:通常建议值为128K 或者256K;
SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法;
软中断:如果Linux 内核版本支持RPS(2.6.35 以上版本),开启RPS 后可以实现软中断,提升网络吞吐量。RPS根据数据包的源地址,目的地址以及目的和源端口,计算出一个hash 值,然后根据这个hash 值来选择软中断运行的cpu,从上层来看,也就是说将每个连接和cpu 绑定,并通过这个hash 值,来均衡软中断在多个cpu 上,提升网络并行处理性能
IO类型介绍
BIO(Block input output 块设备输入输出)
一个客户端对应一个IO线程
Socket编程就是BIO,一个socket连接一个处理线程
伪异步IO
将请求连接放入线程池,一对多,但线程还是很宝贵的资源。
NIO (non-blocking IO 非阻塞IO)
一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
NIO的组成:BIO是面向流的,NIO是面向缓冲区的(buffer 缓冲区);BIO的各种流是阻塞的。而NIO是非阻塞的(selector 多路复用器);BIO的Stream是单向的,而NIO的channel是双向的 (channel 通道)
AIO (asynchronous io 异步io)
一个有效请求一个线程,客户端的I/O请求都是由OS(操纵系统)先完成了再通知服务器应用去启动线程进行处理
AIO是发出IO请求后,由操作系统自己去获取IO权限并进行IO操作;NIO则是发出IO请求后,由线程不断尝试获取IO权限,获取到后通知应用程序自己进行IO操作。
多路复用
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
零拷贝
DMA 的全称叫直接内存存取(Direct Memory Access)
传统的
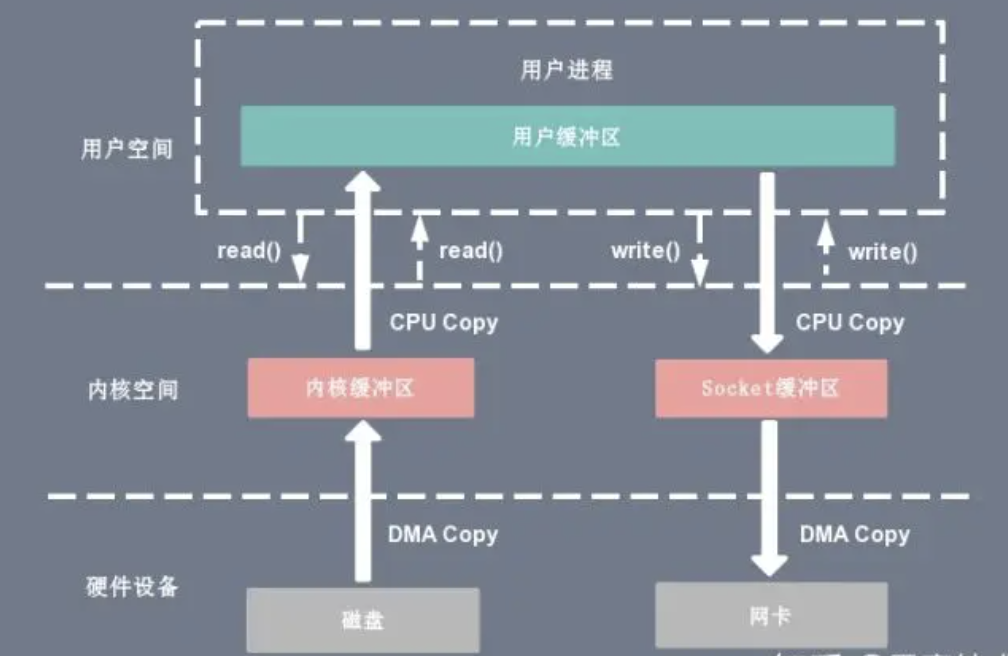
上下文切换:当用户程序向内核发起系统调用时,CPU 将用户进程从用户态切换到内核态;当系统调用返回时,CPU 将用户进程从内核态切换回用户态。
CPU拷贝:由 CPU 直接处理数据的传送,数据拷贝时会一直占用 CPU 的资源。
DMA拷贝:由 CPU 向DMA磁盘控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,从而减轻了 CPU 资源的占有率。
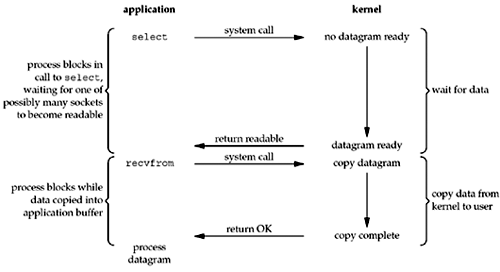
读操作
基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
零拷贝
在 Linux 中零拷贝技术主要有 3 个实现思路:用户态直接 I/O、减少数据拷贝次数以及写时复制技术。
用户态直接 I/O:应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输。这种方式依旧存在用户空间和内核空间的上下文切换,硬件上的数据直接拷贝至了用户空间,不经过内核空间。因此,直接 I/O 不存在内核空间缓冲区和用户空间缓冲区之间的数据拷贝。
减少数据拷贝次数:在数据传输过程中,避免数据在用户空间缓冲区和系统内核空间缓冲区之间的CPU拷贝,以及数据在系统内核空间内的CPU拷贝,这也是当前主流零拷贝技术的实现思路。
写时复制技术:写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么将其拷贝到自己的进程地址空间中,如果只是数据读取操作则不需要进行拷贝操作。
用户态直接IO
用户态直接 I/O 使得应用进程或运行在用户态(user space)下的库函数直接访问硬件设备,数据直接跨过内核进行传输,内核在数据传输过程除了进行必要的虚拟存储配置工作之外,不参与任何其他工作,这种方式能够直接绕过内核,极大提高了性能。
用户态直接 I/O 只能适用于不需要内核缓冲区处理的应用程序,这些应用程序通常在进程地址空间有自己的数据缓存机制,称为自缓存应用程序,如数据库管理系统就是一个代表。其次,这种零拷贝机制会直接操作磁盘 I/O,由于 CPU 和磁盘 I/O 之间的执行时间差距,会造成大量资源的浪费,解决方案是配合异步 I/O 使用。
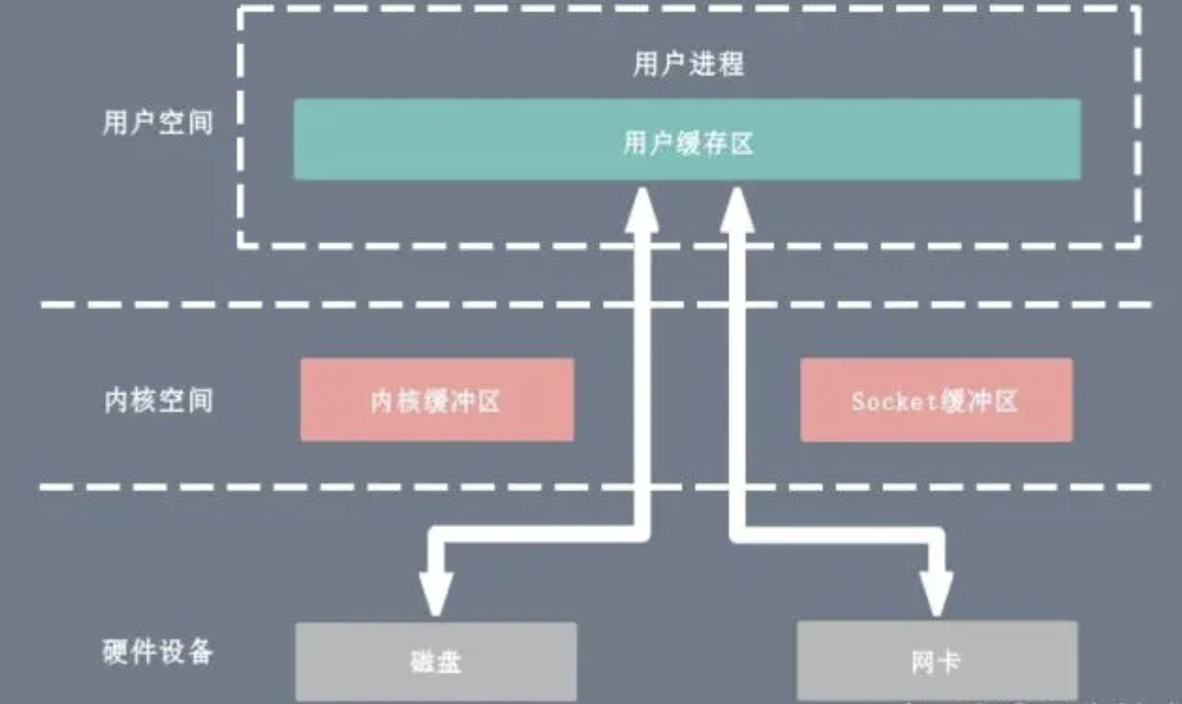
mmap + write
一种零拷贝方式是使用 mmap + write 代替原来的 read + write 方式,减少了 1 次 CPU 拷贝操作。mmap 是 Linux 提供的一种内存映射文件方法,即将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址,mmap + write 的伪代码如下:
tmp_buf = mmap(file_fd, len);
write(socket_fd, tmp_buf, len);
使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射,从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,然而内核读缓冲区(read buffer)仍需将数据到内核写缓冲区(socket buffer),大致的流程如下图所示:
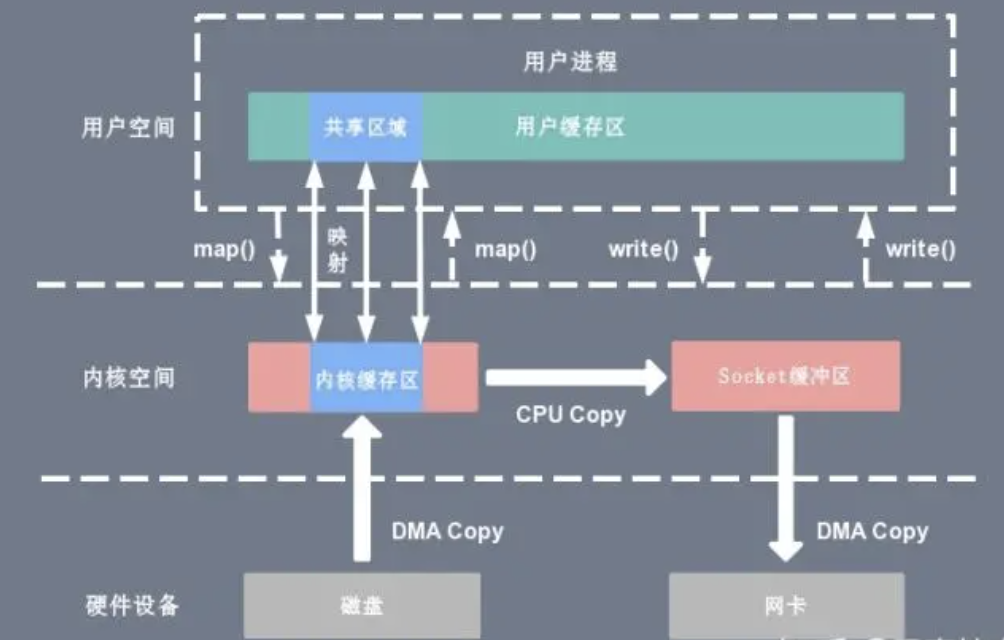
sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:
sendfile(socket_fd, file_fd, len);
复制代码通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
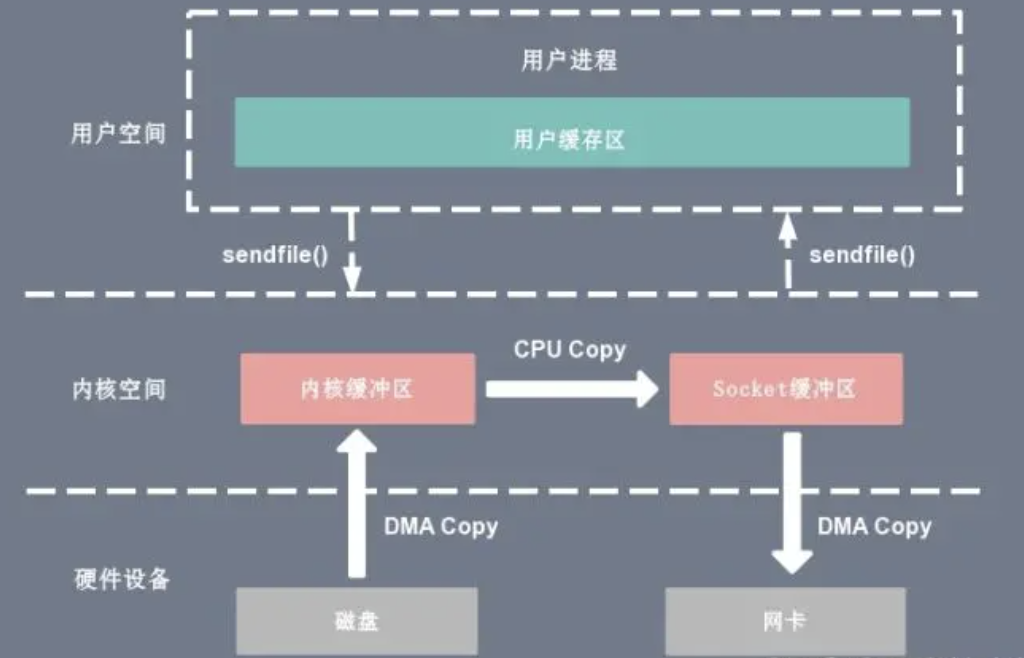
对比
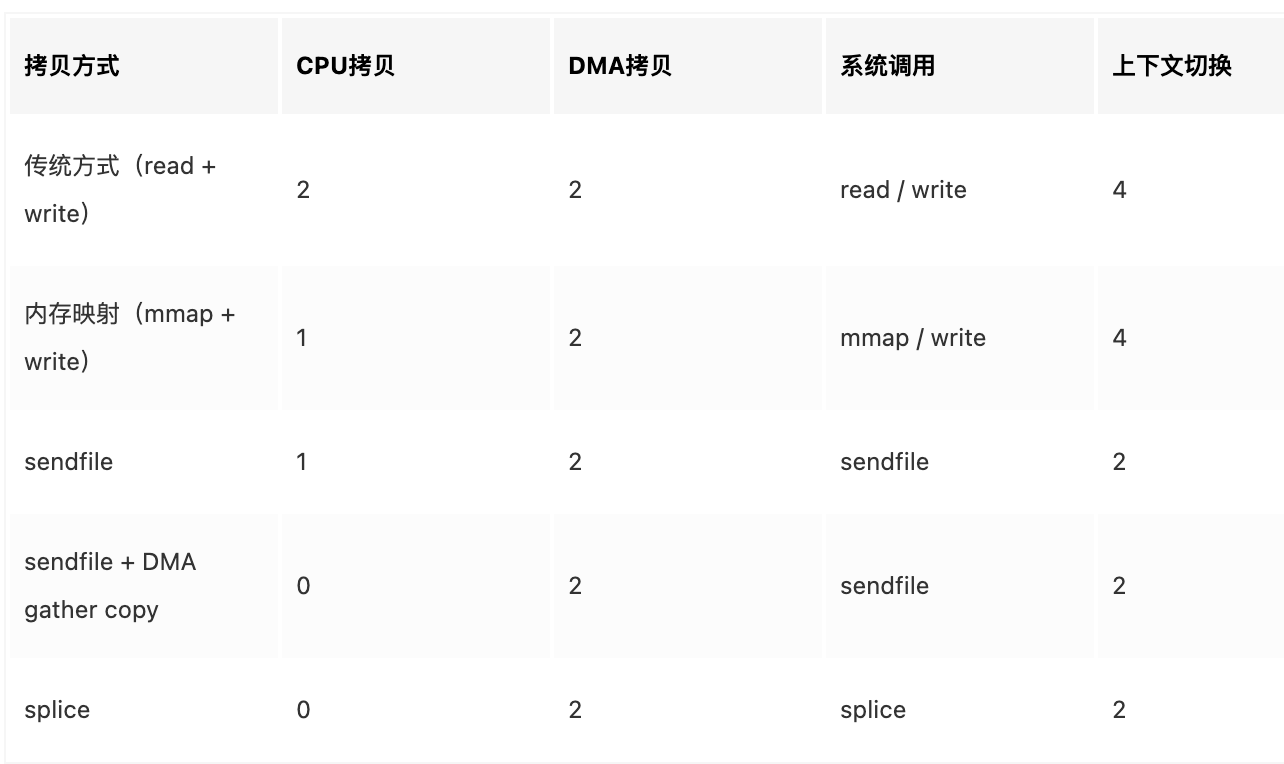
实现
java
java NIO的零拷贝实现是基于mmap+write方式
FileChannel的map方法产生的MappedByteBuffer FileChannel提供了map()方法,该方法可以在一个打开的文件和MappedByteBuffer之间建立一个虚拟内存映射
DirectByteBuffer 是 MappedByteBuffer 的具体实现类,也是通过mmap+write的方式。
FileChannel的transferTo,transferFrom方法是通过sendFile的方式实现
netty
应用层:
ByteBuf 可以通过 wrap 操作把字节数组、ByteBuf、ByteBuffer 包装成一个 ByteBuf 对象, 进而避免了拷贝操作
ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf,避免了内存的拷贝
Netty 提供了 CompositeByteBuf 类,它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免了各个 ByteBuf 之间的拷贝
操作系统层:DefaultFileRegion对FileChannel的tranferTo方法进行了包装,在文件传输时可以将文件缓冲区的数据直接发送到目的通道(Channel)
DirectByteBuffer继承自java noi的MappedByteBuffer,通过mmap+write的方式
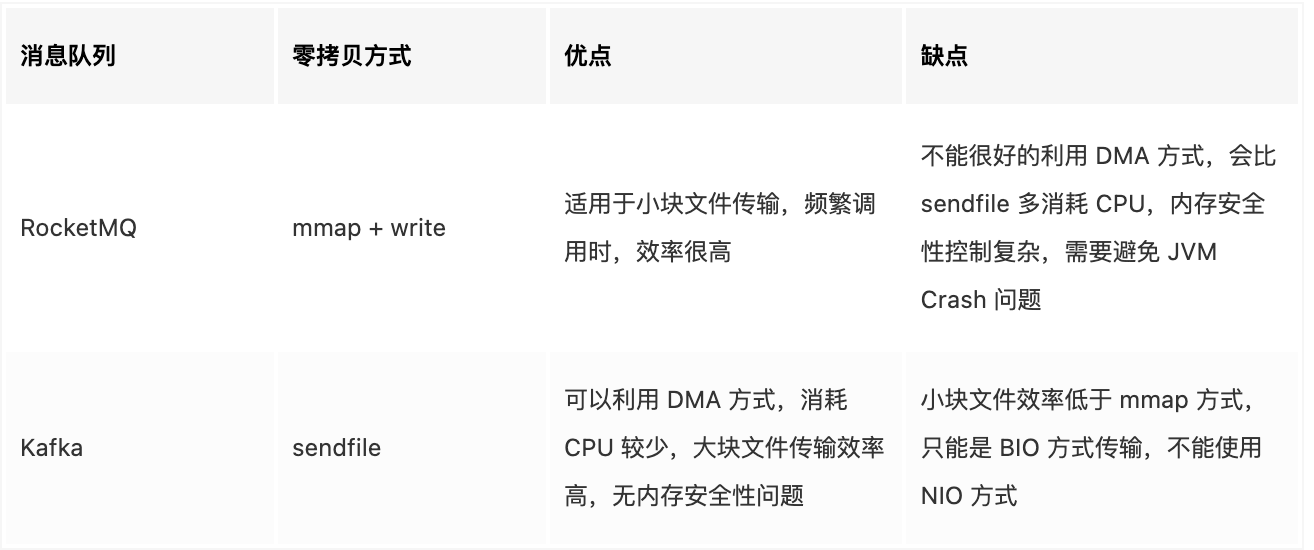
RocketMQ和Kafka
RocketMQ 选择了 mmap + write 这种零拷贝方式,适用于业务级消息这种小块文件的数据持久化和传输;而 Kafka 采用的是 sendfile 这种零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输。但是值得注意的一点是,Kafka 的索引文件使用的是 mmap + write 方式,数据文件使用的是 sendfile 方式。